

Τι είναι τα μεγάλα γλωσσικά μοντέλα;
Τα μοντέλα μεγάλων γλωσσών (LLM) είναι προηγμένα συστήματα τεχνητής νοημοσύνης (AI) σχεδιασμένα να επεξεργάζονται, να κατανοούν και να δημιουργούν κείμενο που μοιάζει με άνθρωπο. Βασίζονται σε τεχνικές βαθιάς μάθησης και εκπαιδεύονται σε τεράστια σύνολα δεδομένων, που συνήθως περιέχουν δισεκατομμύρια λέξεις από διαφορετικές πηγές, όπως ιστότοπους, βιβλία και άρθρα. Αυτή η εκτεταμένη εκπαίδευση δίνει τη δυνατότητα στους LLM να κατανοήσουν τις αποχρώσεις της γλώσσας, της γραμματικής, του πλαισίου και ακόμη και ορισμένες πτυχές της γενικής γνώσης.
Ορισμένα δημοφιλή LLM, όπως το GPT-3 του OpenAI, χρησιμοποιούν έναν τύπο νευρωνικού δικτύου που ονομάζεται μετασχηματιστής, ο οποίος τους επιτρέπει να χειρίζονται πολύπλοκες γλωσσικές εργασίες με αξιοσημείωτη επάρκεια. Αυτά τα μοντέλα μπορούν να εκτελέσουν ένα ευρύ φάσμα εργασιών, όπως:
- Απαντώντας σε ερωτήσεις
- Συνοπτικό κείμενο
- Μετάφραση γλωσσών
- Δημιουργία περιεχομένου
- Ακόμη και η συμμετοχή σε διαδραστικές συνομιλίες με τους χρήστες
Καθώς τα LLM συνεχίζουν να εξελίσσονται, έχουν μεγάλες δυνατότητες για τη βελτίωση και την αυτοματοποίηση διαφόρων εφαρμογών σε όλους τους κλάδους, από την εξυπηρέτηση πελατών και τη δημιουργία περιεχομένου έως την εκπαίδευση και την έρευνα. Ωστόσο, εγείρουν επίσης ηθικές και κοινωνικές ανησυχίες, όπως μεροληπτική συμπεριφορά ή κακή χρήση, που πρέπει να αντιμετωπιστούν καθώς η τεχνολογία προχωρά.

Δημοφιλή παραδείγματα μεγάλων γλωσσικών μοντέλων
Ακολουθούν μερικά σημαντικά παραδείγματα LLM που χρησιμοποιούνται ευρέως σε διαφορετικούς κλάδους της βιομηχανίας:
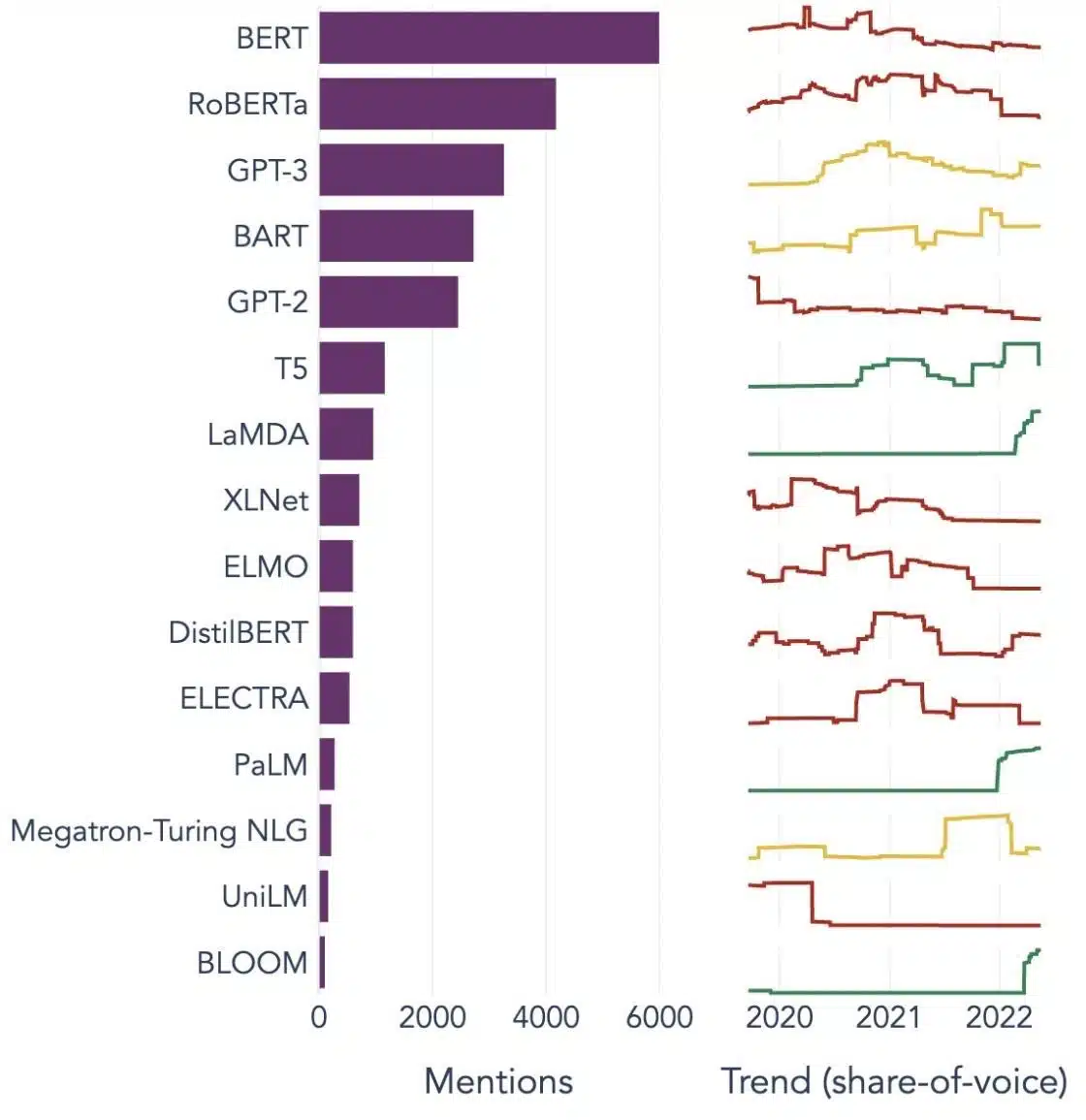
Πηγή εικόνας: Προς την Επιστήμη των Δεδομένων
Πώς εκπαιδεύονται τα μοντέλα LLM;
Η εκπαίδευση μεγάλων γλωσσικών μοντέλων (LLM) είναι ένα μεγάλο κατόρθωμα που περιλαμβάνει πολλά κρίσιμα βήματα. Ακολουθεί μια απλοποιημένη, βήμα προς βήμα περίληψη της διαδικασίας:
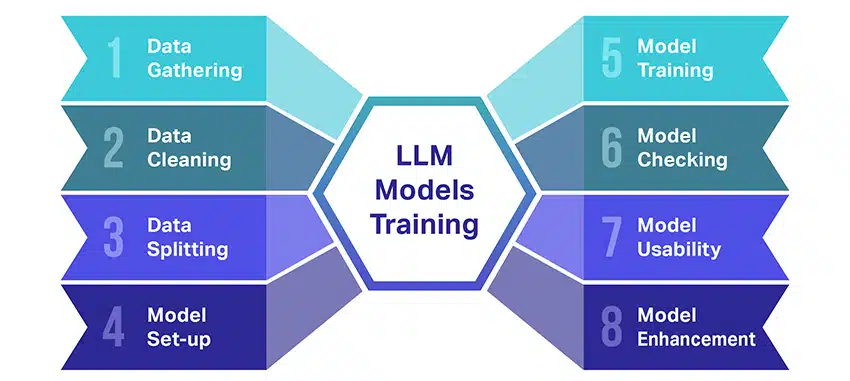
- Συλλογή δεδομένων κειμένου: Η εκπαίδευση ενός LLM ξεκινά με τη συλλογή ενός τεράστιου όγκου δεδομένων κειμένου. Αυτά τα δεδομένα μπορούν να προέρχονται από βιβλία, ιστότοπους, άρθρα ή πλατφόρμες μέσων κοινωνικής δικτύωσης. Στόχος είναι να αποτυπωθεί η πλούσια ποικιλομορφία της ανθρώπινης γλώσσας.
- Εκκαθάριση δεδομένων: Τα ακατέργαστα δεδομένα κειμένου στη συνέχεια τακτοποιούνται σε μια διαδικασία που ονομάζεται προεπεξεργασία. Αυτό περιλαμβάνει εργασίες όπως η αφαίρεση ανεπιθύμητων χαρακτήρων, η διάσπαση του κειμένου σε μικρότερα μέρη που ονομάζονται tokens και η μεταφορά του σε μια μορφή με την οποία μπορεί να λειτουργήσει το μοντέλο.
- Διαχωρισμός δεδομένων: Στη συνέχεια, τα καθαρά δεδομένα χωρίζονται σε δύο σύνολα. Ένα σύνολο, τα δεδομένα εκπαίδευσης, θα χρησιμοποιηθεί για την εκπαίδευση του μοντέλου. Το άλλο σύνολο, τα δεδομένα επικύρωσης, θα χρησιμοποιηθεί αργότερα για τον έλεγχο της απόδοσης του μοντέλου.
- Ρύθμιση του μοντέλου: Στη συνέχεια ορίζεται η δομή του LLM, γνωστή ως αρχιτεκτονική. Αυτό περιλαμβάνει την επιλογή του τύπου του νευρωνικού δικτύου και τη λήψη απόφασης για διάφορες παραμέτρους, όπως ο αριθμός των επιπέδων και των κρυφών μονάδων μέσα στο δίκτυο.
- Εκπαίδευση του μοντέλου: Η ουσιαστική εκπαίδευση τώρα ξεκινά. Το μοντέλο LLM μαθαίνει κοιτάζοντας τα δεδομένα εκπαίδευσης, κάνοντας προβλέψεις με βάση όσα έχει μάθει μέχρι στιγμής και στη συνέχεια προσαρμόζοντας τις εσωτερικές του παραμέτρους για να μειώσει τη διαφορά μεταξύ των προβλέψεών του και των πραγματικών δεδομένων.
- Έλεγχος του μοντέλου: Η εκμάθηση του μοντέλου LLM ελέγχεται χρησιμοποιώντας τα δεδομένα επικύρωσης. Αυτό βοηθά να δείτε πόσο καλά αποδίδει το μοντέλο και να τροποποιήσετε τις ρυθμίσεις του για καλύτερη απόδοση.
- Χρησιμοποιώντας το μοντέλο: Μετά την εκπαίδευση και την αξιολόγηση, το μοντέλο LLM είναι έτοιμο για χρήση. Τώρα μπορεί να ενσωματωθεί σε εφαρμογές ή συστήματα όπου θα δημιουργεί κείμενο με βάση τις νέες εισόδους που έχει δώσει.
- Βελτίωση του μοντέλου: Τέλος, υπάρχει πάντα περιθώριο βελτίωσης. Το μοντέλο LLM μπορεί να βελτιωθεί περαιτέρω με την πάροδο του χρόνου, χρησιμοποιώντας ενημερωμένα δεδομένα ή προσαρμόζοντας ρυθμίσεις με βάση τα σχόλια και τη χρήση στον πραγματικό κόσμο.
Θυμηθείτε, αυτή η διαδικασία απαιτεί σημαντικούς υπολογιστικούς πόρους, όπως ισχυρές μονάδες επεξεργασίας και μεγάλο χώρο αποθήκευσης, καθώς και εξειδικευμένες γνώσεις στη μηχανική εκμάθηση. Γι' αυτό συνήθως γίνεται από ειδικούς ερευνητικούς οργανισμούς ή εταιρείες με πρόσβαση στην απαραίτητη υποδομή και τεχνογνωσία.
Το LLM βασίζεται σε εποπτευόμενη ή χωρίς επίβλεψη μάθηση;
Τα μεγάλα γλωσσικά μοντέλα συνήθως εκπαιδεύονται χρησιμοποιώντας μια μέθοδο που ονομάζεται εποπτευόμενη μάθηση. Με απλά λόγια, αυτό σημαίνει ότι μαθαίνουν από παραδείγματα που τους δείχνουν τις σωστές απαντήσεις.
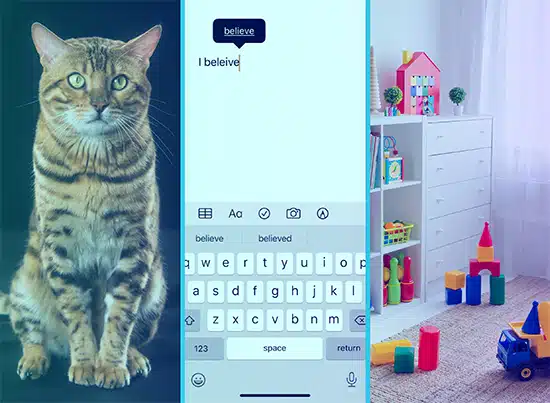 Φανταστείτε ότι διδάσκετε σε ένα παιδί λέξεις δείχνοντάς του εικόνες. Τους δείχνεις μια εικόνα μιας γάτας και λες «γάτα» και μαθαίνουν να συνδέουν αυτή την εικόνα με τη λέξη. Έτσι λειτουργεί η εποπτευόμενη μάθηση. Στο μοντέλο δίνονται πολλά κείμενα (οι «εικόνες») και τα αντίστοιχα αποτελέσματα (οι «λέξεις») και μαθαίνει να τα αντιστοιχίζει.
Φανταστείτε ότι διδάσκετε σε ένα παιδί λέξεις δείχνοντάς του εικόνες. Τους δείχνεις μια εικόνα μιας γάτας και λες «γάτα» και μαθαίνουν να συνδέουν αυτή την εικόνα με τη λέξη. Έτσι λειτουργεί η εποπτευόμενη μάθηση. Στο μοντέλο δίνονται πολλά κείμενα (οι «εικόνες») και τα αντίστοιχα αποτελέσματα (οι «λέξεις») και μαθαίνει να τα αντιστοιχίζει.
Έτσι, εάν τροφοδοτήσετε ένα LLM μια πρόταση, προσπαθεί να προβλέψει την επόμενη λέξη ή φράση με βάση αυτά που έχει μάθει από τα παραδείγματα. Με αυτόν τον τρόπο, μαθαίνει πώς να δημιουργεί κείμενο που έχει νόημα και ταιριάζει στο πλαίσιο.
Τούτου λεχθέντος, μερικές φορές οι LLM χρησιμοποιούν επίσης λίγη μάθηση χωρίς επίβλεψη. Αυτό είναι σαν να αφήνετε το παιδί να εξερευνήσει ένα δωμάτιο γεμάτο διαφορετικά παιχνίδια και να τα μάθει μόνο του. Το μοντέλο εξετάζει δεδομένα χωρίς ετικέτα, μοτίβα μάθησης και δομές χωρίς να του λέει τις «σωστές» απαντήσεις.
Η εποπτευόμενη μάθηση χρησιμοποιεί δεδομένα που έχουν επισημανθεί με εισόδους και εξόδους, σε αντίθεση με την μάθηση χωρίς επίβλεψη, η οποία δεν χρησιμοποιεί δεδομένα εξόδου με ετικέτα.
Με λίγα λόγια, οι LLM εκπαιδεύονται κυρίως χρησιμοποιώντας εποπτευόμενη μάθηση, αλλά μπορούν επίσης να χρησιμοποιήσουν μάθηση χωρίς επίβλεψη για να ενισχύσουν τις δυνατότητές τους, όπως για διερευνητική ανάλυση και μείωση διαστάσεων.
Ποιος είναι ο όγκος δεδομένων (σε GB) που απαιτείται για την εκπαίδευση ενός μοντέλου μεγάλης γλώσσας;
Ο κόσμος των δυνατοτήτων για την αναγνώριση δεδομένων ομιλίας και τις εφαρμογές φωνής είναι τεράστιος και χρησιμοποιούνται σε πολλές βιομηχανίες για μια πληθώρα εφαρμογών.
Η εκπαίδευση ενός μεγάλου γλωσσικού μοντέλου δεν είναι μια διαδικασία που ταιριάζει σε όλους, ειδικά όταν πρόκειται για τα δεδομένα που απαιτούνται. Εξαρτάται από ένα σωρό πράγματα:
- Ο σχεδιασμός του μοντέλου.
- Τι δουλειά χρειάζεται να κάνει;
- Ο τύπος των δεδομένων που χρησιμοποιείτε.
- Πόσο καλά θέλετε να αποδώσει;
Τούτου λεχθέντος, η εκπαίδευση LLM συνήθως απαιτεί τεράστιο όγκο δεδομένων κειμένου. Αλλά για πόσο μαζικό μιλάμε; Λοιπόν, σκεφτείτε πολύ πέρα από τα gigabyte (GB). Συνήθως εξετάζουμε terabyte (TB) ή ακόμα και petabyte (PB) δεδομένων.
Σκεφτείτε το GPT-3, ένα από τα μεγαλύτερα LLMs. Εκπαιδεύεται σε 570 GB δεδομένων κειμένου. Τα μικρότερα LLM μπορεί να χρειάζονται λιγότερα – ίσως 10-20 GB ή ακόμα και 1 GB gigabyte – αλλά είναι ακόμα πολλά.

Δεν είναι όμως μόνο το μέγεθος των δεδομένων. Σημασία έχει και η ποιότητα. Τα δεδομένα πρέπει να είναι καθαρά και ποικίλα για να βοηθήσουν το μοντέλο να μάθει αποτελεσματικά. Και δεν μπορείτε να ξεχάσετε άλλα βασικά κομμάτια του παζλ, όπως την υπολογιστική ισχύ που χρειάζεστε, τους αλγόριθμους που χρησιμοποιείτε για εκπαίδευση και τη ρύθμιση υλικού που έχετε. Όλοι αυτοί οι παράγοντες παίζουν μεγάλο ρόλο στην εκπαίδευση ενός LLM.
Η άνοδος των μεγάλων γλωσσικών μοντέλων: Γιατί έχουν σημασία
Τα LLM δεν είναι πλέον απλώς μια ιδέα ή ένα πείραμα. Διαδραματίζουν όλο και περισσότερο κρίσιμο ρόλο στο ψηφιακό μας τοπίο. Γιατί όμως συμβαίνει αυτό; Τι κάνει αυτά τα LLM τόσο σημαντικά; Ας εμβαθύνουμε σε ορισμένους βασικούς παράγοντες.
Μαεστρία στη Μίμηση Ανθρώπινου Κειμένου
Τα LLM έχουν αλλάξει τον τρόπο με τον οποίο χειριζόμαστε εργασίες που βασίζονται στη γλώσσα. Κατασκευασμένα με χρήση ισχυρών αλγορίθμων μηχανικής μάθησης, αυτά τα μοντέλα είναι εξοπλισμένα με την ικανότητα κατανόησης των αποχρώσεων της ανθρώπινης γλώσσας, συμπεριλαμβανομένων των περιεχομένων, των συναισθημάτων και ακόμη και του σαρκασμού, σε κάποιο βαθμό. Αυτή η ικανότητα μίμησης της ανθρώπινης γλώσσας δεν είναι μια απλή καινοτομία, έχει σημαντικές επιπτώσεις.
Οι προηγμένες ικανότητες δημιουργίας κειμένου των LLM μπορούν να βελτιώσουν τα πάντα, από τη δημιουργία περιεχομένου έως τις αλληλεπιδράσεις με την εξυπηρέτηση πελατών.
Φανταστείτε να είστε σε θέση να κάνετε μια σύνθετη ερώτηση σε έναν ψηφιακό βοηθό και να λαμβάνετε μια απάντηση που όχι μόνο έχει νόημα, αλλά είναι επίσης συνεκτική, σχετική και εκφράζεται με τόνο συνομιλίας. Αυτό επιτρέπουν τα LLM. Τροφοδοτούν μια πιο διαισθητική και ελκυστική αλληλεπίδραση ανθρώπου-μηχανής, εμπλουτίζουν τις εμπειρίες των χρηστών και εκδημοκρατίζουν την πρόσβαση στις πληροφορίες.
Προσιτή Υπολογιστική Ισχύς
Η άνοδος των LLMs δεν θα ήταν δυνατή χωρίς παράλληλες εξελίξεις στον τομέα των υπολογιστών. Πιο συγκεκριμένα, ο εκδημοκρατισμός των υπολογιστικών πόρων έχει παίξει σημαντικό ρόλο στην εξέλιξη και υιοθέτηση των LLM.
Οι πλατφόρμες που βασίζονται στο cloud προσφέρουν άνευ προηγουμένου πρόσβαση σε υπολογιστικούς πόρους υψηλής απόδοσης. Με αυτόν τον τρόπο, ακόμη και οργανισμοί μικρής κλίμακας και ανεξάρτητοι ερευνητές μπορούν να εκπαιδεύσουν εξελιγμένα μοντέλα μηχανικής μάθησης.
Επιπλέον, οι βελτιώσεις στις μονάδες επεξεργασίας (όπως οι GPU και οι TPU), σε συνδυασμό με την άνοδο των κατανεμημένων υπολογιστών, κατέστησαν εφικτή την εκπαίδευση μοντέλων με δισεκατομμύρια παραμέτρους. Αυτή η αυξημένη προσβασιμότητα της υπολογιστικής ισχύος επιτρέπει την ανάπτυξη και την επιτυχία των LLM, οδηγώντας σε περισσότερη καινοτομία και εφαρμογές στον τομέα.
Μετατόπιση των προτιμήσεων των καταναλωτών
Οι καταναλωτές σήμερα δεν θέλουν απλώς απαντήσεις. θέλουν ελκυστικές και σχετικές αλληλεπιδράσεις. Καθώς περισσότεροι άνθρωποι μεγαλώνουν χρησιμοποιώντας ψηφιακή τεχνολογία, είναι προφανές ότι αυξάνεται η ανάγκη για τεχνολογία που μοιάζει πιο φυσική και ανθρώπινη. Τα LLM προσφέρουν μια απαράμιλλη ευκαιρία να ανταποκριθούν σε αυτές τις προσδοκίες. Δημιουργώντας κείμενο που μοιάζει με άνθρωπο, αυτά τα μοντέλα μπορούν να δημιουργήσουν ελκυστικές και δυναμικές ψηφιακές εμπειρίες, οι οποίες μπορούν να αυξήσουν την ικανοποίηση και την αφοσίωση των χρηστών. Είτε πρόκειται για chatbots AI που παρέχουν εξυπηρέτηση πελατών είτε για φωνητικούς βοηθούς που παρέχουν ενημερώσεις ειδήσεων, οι LLM εγκαινιάζουν μια εποχή τεχνητής νοημοσύνης που μας καταλαβαίνει καλύτερα.
The Unstructured Data Goldmine
Τα μη δομημένα δεδομένα, όπως τα email, οι αναρτήσεις στα μέσα κοινωνικής δικτύωσης και οι κριτικές πελατών, αποτελούν έναν θησαυρό πληροφοριών. Υπολογίζεται ότι έχει τελειώσει 80% των εταιρικών δεδομένων είναι αδόμητα και αυξάνεται με ρυθμό 55% ανά έτος. Αυτά τα δεδομένα είναι ένα χρυσωρυχείο για τις επιχειρήσεις εάν αξιοποιηθούν σωστά.
Τα LLM παίζουν εδώ, με την ικανότητά τους να επεξεργάζονται και να κατανοούν τέτοια δεδομένα σε κλίμακα. Μπορούν να χειριστούν εργασίες όπως ανάλυση συναισθήματος, ταξινόμηση κειμένου, εξαγωγή πληροφοριών και άλλα, παρέχοντας έτσι πολύτιμες πληροφορίες.
Είτε πρόκειται για τον εντοπισμό τάσεων από αναρτήσεις στα μέσα κοινωνικής δικτύωσης είτε για τη μέτρηση του συναισθήματος των πελατών από κριτικές, τα LLM βοηθούν τις επιχειρήσεις να πλοηγηθούν σε μεγάλο όγκο μη δομημένων δεδομένων και να λάβουν αποφάσεις βάσει δεδομένων.
Η διευρυνόμενη αγορά NLP
Οι δυνατότητες των LLMs αντικατοπτρίζονται στην ταχέως αναπτυσσόμενη αγορά για την επεξεργασία φυσικής γλώσσας (NLP). Οι αναλυτές προβλέπουν ότι η αγορά NLP θα επεκταθεί από 11 δισεκατομμύρια δολάρια το 2020 σε πάνω από 35 δισεκατομμύρια δολάρια έως το 2026. Αλλά δεν είναι μόνο το μέγεθος της αγοράς που επεκτείνεται. Τα ίδια τα μοντέλα αυξάνονται επίσης, τόσο σε φυσικό μέγεθος όσο και σε αριθμό παραμέτρων που χειρίζονται. Η εξέλιξη των LLM με τα χρόνια, όπως φαίνεται στο παρακάτω σχήμα (πηγή εικόνας: σύνδεσμος), υπογραμμίζει την αυξανόμενη πολυπλοκότητα και χωρητικότητά τους.
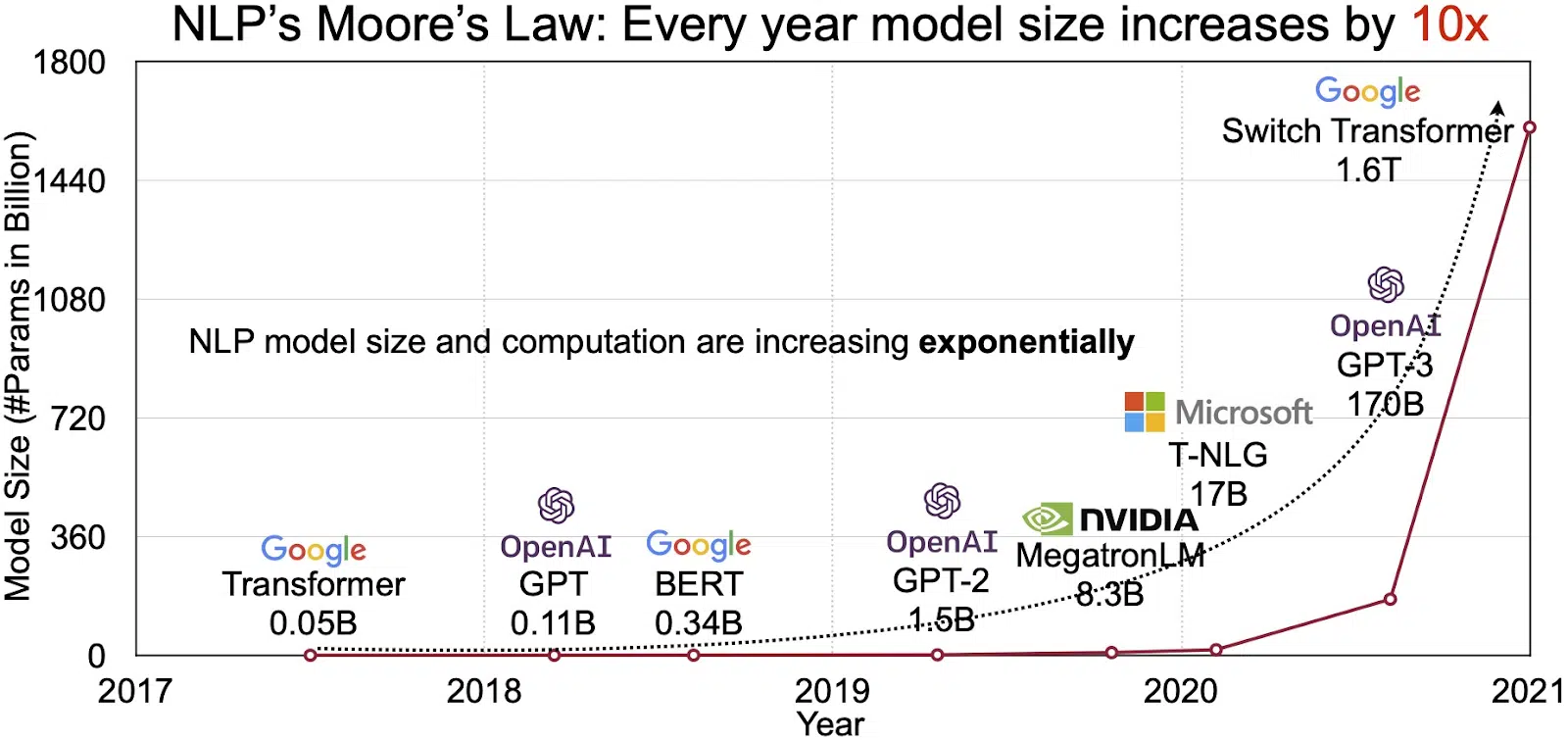
Δημοφιλείς περιπτώσεις χρήσης μεγάλων γλωσσικών μοντέλων
Ακολουθούν μερικές από τις κορυφαίες και πιο διαδεδομένες περιπτώσεις χρήσης LLM:
- Δημιουργία κειμένου φυσικής γλώσσας: Τα μεγάλα γλωσσικά μοντέλα (LLM) συνδυάζουν τη δύναμη της τεχνητής νοημοσύνης και της υπολογιστικής γλωσσολογίας για να παράγουν αυτόνομα κείμενα σε φυσική γλώσσα. Μπορούν να καλύψουν διαφορετικές ανάγκες των χρηστών, όπως να γράφουν άρθρα, να δημιουργούν τραγούδια ή να συμμετέχουν σε συνομιλίες με χρήστες.
- Μετάφραση μέσω μηχανών: Τα LLM μπορούν να χρησιμοποιηθούν αποτελεσματικά για τη μετάφραση κειμένου μεταξύ οποιουδήποτε ζεύγους γλωσσών. Αυτά τα μοντέλα εκμεταλλεύονται αλγόριθμους βαθιάς μάθησης όπως επαναλαμβανόμενα νευρωνικά δίκτυα για να κατανοήσουν τη γλωσσική δομή τόσο των γλωσσών πηγής όσο και των γλωσσών-στόχων, διευκολύνοντας έτσι τη μετάφραση του κειμένου πηγής στην επιθυμητή γλώσσα.
- Δημιουργία πρωτότυπου περιεχομένου: Τα LLM έχουν ανοίξει δρόμους για τις μηχανές να παράγουν συνεκτικό και λογικό περιεχόμενο. Αυτό το περιεχόμενο μπορεί να χρησιμοποιηθεί για τη δημιουργία αναρτήσεων ιστολογίου, άρθρων και άλλων τύπων περιεχομένου. Τα μοντέλα αξιοποιούν τη βαθιά εμπειρία τους σε βάθος μάθησης για να μορφοποιήσουν και να δομήσουν το περιεχόμενο με νέο και φιλικό προς τον χρήστη τρόπο.
- Ανάλυση συναισθημάτων: Μια ενδιαφέρουσα εφαρμογή των μεγάλων γλωσσικών μοντέλων είναι η ανάλυση συναισθήματος. Σε αυτό, το μοντέλο εκπαιδεύεται να αναγνωρίζει και να κατηγοριοποιεί τις συναισθηματικές καταστάσεις και τα συναισθήματα που υπάρχουν στο σχολιασμένο κείμενο. Το λογισμικό μπορεί να αναγνωρίσει συναισθήματα όπως η θετικότητα, η αρνητικότητα, η ουδετερότητα και άλλα περίπλοκα συναισθήματα. Αυτό μπορεί να προσφέρει πολύτιμες πληροφορίες για τα σχόλια των πελατών και τις απόψεις σχετικά με διάφορα προϊόντα και υπηρεσίες.
- Κατανόηση, περίληψη και ταξινόμηση κειμένου: Τα LLM δημιουργούν μια βιώσιμη δομή για το λογισμικό AI για την ερμηνεία του κειμένου και του πλαισίου του. Δίνοντας οδηγίες στο μοντέλο να κατανοεί και να εξετάζει τεράστιες ποσότητες δεδομένων, τα LLM επιτρέπουν στα μοντέλα τεχνητής νοημοσύνης να κατανοούν, να συνοψίζουν, ακόμη και να κατηγοριοποιούν κείμενο σε διάφορες μορφές και μοτίβα.
- Απαντώντας σε ερωτήσεις: Τα μεγάλα μοντέλα γλώσσας εξοπλίζουν τα συστήματα Απάντησης Ερωτήσεων (QA) με την ικανότητα να αντιλαμβάνονται με ακρίβεια και να ανταποκρίνονται στο ερώτημα φυσικής γλώσσας ενός χρήστη. Στα δημοφιλή παραδείγματα αυτής της περίπτωσης χρήσης περιλαμβάνονται τα ChatGPT και BERT, τα οποία εξετάζουν το πλαίσιο ενός ερωτήματος και εξετάζουν μια τεράστια συλλογή κειμένων για να παρέχουν σχετικές απαντήσεις σε ερωτήσεις των χρηστών.

Επισήμανση μέρους του λόγου (POS).
Οι λέξεις στις προτάσεις επισημαίνονται με τη γραμματική τους λειτουργία, όπως ρήματα, ουσιαστικά, επίθετα κ.λπ. Αυτή η διαδικασία βοηθά το μοντέλο να κατανοήσει τη γραμματική και τους δεσμούς μεταξύ των λέξεων.

Αναγνωρισμένη ονομασία οντότητας (NER)
Οι επώνυμες οντότητες όπως οργανισμοί, τοποθεσίες και άτομα μέσα σε μια πρόταση επισημαίνονται. Αυτή η άσκηση βοηθά το μοντέλο να ερμηνεύσει τις σημασιολογικές έννοιες των λέξεων και των φράσεων και παρέχει πιο ακριβείς απαντήσεις.

Ανάλυση συναισθημάτων
Τα δεδομένα κειμένου αποδίδονται ετικέτες συναισθήματος όπως θετικό, ουδέτερο ή αρνητικό, βοηθώντας το μοντέλο να κατανοήσει τον συναισθηματικό τόνο των προτάσεων. Είναι ιδιαίτερα χρήσιμο για την απάντηση σε ερωτήματα που αφορούν συναισθήματα και απόψεις.
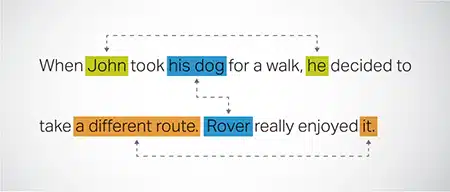
Ψήφισμα αναφοράς
Προσδιορισμός και επίλυση περιπτώσεων όπου η ίδια οντότητα αναφέρεται σε διαφορετικά μέρη ενός κειμένου. Αυτό το βήμα βοηθά το μοντέλο να κατανοήσει το πλαίσιο της πρότασης, οδηγώντας έτσι σε συνεκτικές απαντήσεις.
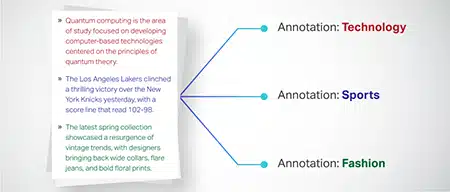
Ταξινόμηση κειμένου
Τα δεδομένα κειμένου κατηγοριοποιούνται σε προκαθορισμένες ομάδες, όπως κριτικές προϊόντων ή άρθρα ειδήσεων. Αυτό βοηθά το μοντέλο να διακρίνει το είδος ή το θέμα του κειμένου, δημιουργώντας πιο κατάλληλες απαντήσεις.
Προσφορά Shaip
Σάιπ προσφέρει ένα ευρύ φάσμα υπηρεσιών για να βοηθήσει τους οργανισμούς να διαχειρίζονται, να αναλύουν και να αξιοποιούν στο έπακρο τα δεδομένα τους.
Data Web-Scraping
Μια βασική υπηρεσία που προσφέρει η Shaip είναι η απόξεση δεδομένων. Αυτό περιλαμβάνει την εξαγωγή δεδομένων από διευθύνσεις URL για συγκεκριμένο τομέα. Χρησιμοποιώντας αυτοματοποιημένα εργαλεία και τεχνικές, η Shaip μπορεί γρήγορα και αποτελεσματικά να σκουπίσει μεγάλο όγκο δεδομένων από διάφορους ιστότοπους, εγχειρίδια προϊόντων, τεχνική τεκμηρίωση, διαδικτυακά φόρουμ, διαδικτυακές κριτικές, δεδομένα εξυπηρέτησης πελατών, ρυθμιστικά έγγραφα βιομηχανίας κ.λπ. Αυτή η διαδικασία μπορεί να είναι ανεκτίμητη για τις επιχειρήσεις όταν συλλέγοντας σχετικά και συγκεκριμένα δεδομένα από πληθώρα πηγών.

Μηχανική μετάφραση
Αναπτύξτε μοντέλα χρησιμοποιώντας εκτεταμένα πολύγλωσσα σύνολα δεδομένων σε συνδυασμό με αντίστοιχες μεταγραφές για τη μετάφραση κειμένου σε διάφορες γλώσσες. Αυτή η διαδικασία βοηθά στην εξάλειψη των γλωσσικών εμποδίων και προωθεί την προσβασιμότητα των πληροφοριών.
Ταξονομία Εξαγωγή & Δημιουργία
Το Shaip μπορεί να βοηθήσει στην εξαγωγή και τη δημιουργία ταξινόμησης. Αυτό περιλαμβάνει την ταξινόμηση και την κατηγοριοποίηση των δεδομένων σε μια δομημένη μορφή που αντανακλά τις σχέσεις μεταξύ διαφορετικών σημείων δεδομένων. Αυτό μπορεί να είναι ιδιαίτερα χρήσιμο για τις επιχειρήσεις στην οργάνωση των δεδομένων τους, καθιστώντας τα πιο προσιτά και ευκολότερα στην ανάλυση. Για παράδειγμα, σε μια επιχείρηση ηλεκτρονικού εμπορίου, τα δεδομένα προϊόντων μπορεί να κατηγοριοποιηθούν με βάση τον τύπο του προϊόντος, τη μάρκα, την τιμή κ.λπ., διευκολύνοντας τους πελάτες να πλοηγηθούν στον κατάλογο προϊόντων.
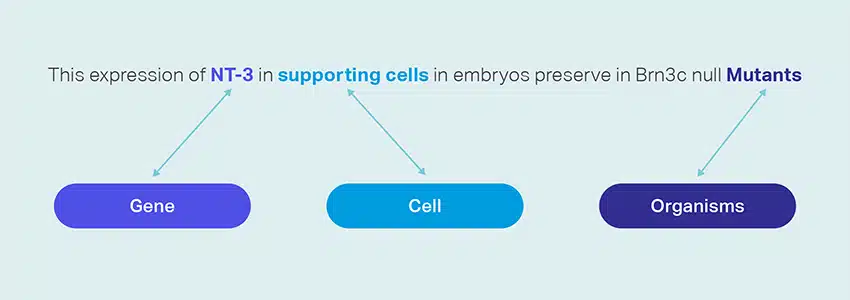
Συλλογή δεδομένων
Οι υπηρεσίες συλλογής δεδομένων μας παρέχουν κρίσιμα δεδομένα πραγματικού ή συνθετικού κόσμου που είναι απαραίτητα για την εκπαίδευση αλγορίθμων παραγωγής τεχνητής νοημοσύνης και τη βελτίωση της ακρίβειας και της αποτελεσματικότητας των μοντέλων σας. Τα δεδομένα προέρχονται αμερόληπτα, ηθικά και υπεύθυνα, λαμβάνοντας παράλληλα υπόψη το απόρρητο και την ασφάλεια των δεδομένων.

Ερώτηση & Απάντηση
Η απάντηση ερωτήσεων (QA) είναι ένα υποπεδίο της επεξεργασίας φυσικής γλώσσας που επικεντρώνεται στην αυτόματη απάντηση σε ερωτήσεις στην ανθρώπινη γλώσσα. Τα συστήματα διασφάλισης ποιότητας εκπαιδεύονται σε εκτενές κείμενο και κώδικα, δίνοντάς τους τη δυνατότητα να χειρίζονται διάφορους τύπους ερωτήσεων, συμπεριλαμβανομένων πραγματικών, οριστικών και βασισμένων σε απόψεις. Η γνώση του τομέα είναι ζωτικής σημασίας για την ανάπτυξη μοντέλων διασφάλισης ποιότητας προσαρμοσμένα σε συγκεκριμένους τομείς όπως η υποστήριξη πελατών, η υγειονομική περίθαλψη ή η αλυσίδα εφοδιασμού. Ωστόσο, οι γενετικές προσεγγίσεις QA επιτρέπουν στα μοντέλα να δημιουργούν κείμενο χωρίς γνώση τομέα, βασιζόμενα αποκλειστικά στο πλαίσιο.
Η ομάδα ειδικών μας μπορεί να μελετήσει σχολαστικά ολοκληρωμένα έγγραφα ή εγχειρίδια για να δημιουργήσει ζεύγη Ερωτήσεων-Απαντήσεων, διευκολύνοντας τη δημιουργία Generative AI για επιχειρήσεις. Αυτή η προσέγγιση μπορεί να αντιμετωπίσει αποτελεσματικά τα ερωτήματα των χρηστών με την εξόρυξη σχετικών πληροφοριών από ένα εκτεταμένο σώμα. Οι πιστοποιημένοι ειδικοί μας διασφαλίζουν την παραγωγή ζευγών Q&A κορυφαίας ποιότητας που εκτείνονται σε διάφορα θέματα και τομείς.

Σύνοψη κειμένου
Οι ειδικοί μας είναι σε θέση να αποστάζουν περιεκτικές συνομιλίες ή μακροσκελείς διαλόγους, παρέχοντας συνοπτικές και διορατικές περιλήψεις από εκτενή δεδομένα κειμένου.

Δημιουργία κειμένου
Εκπαιδεύστε μοντέλα χρησιμοποιώντας ένα ευρύ σύνολο δεδομένων κειμένου σε διάφορα στυλ, όπως άρθρα ειδήσεων, μυθοπλασία και ποίηση. Αυτά τα μοντέλα μπορούν στη συνέχεια να δημιουργήσουν διάφορους τύπους περιεχομένου, συμπεριλαμβανομένων ειδήσεων, εγγραφών ιστολογίου ή αναρτήσεων στα μέσα κοινωνικής δικτύωσης, προσφέροντας μια οικονομικά αποδοτική λύση και εξοικονόμηση χρόνου για τη δημιουργία περιεχομένου.
Αναγνώριση ομιλίας
Αναπτύξτε μοντέλα ικανά να κατανοούν την προφορική γλώσσα για διάφορες εφαρμογές. Αυτό περιλαμβάνει βοηθούς που ενεργοποιούνται με φωνή, λογισμικό υπαγόρευσης και εργαλεία μετάφρασης σε πραγματικό χρόνο. Η διαδικασία περιλαμβάνει τη χρήση ενός ολοκληρωμένου συνόλου δεδομένων που αποτελείται από ηχογραφήσεις της ομιλούμενης γλώσσας, σε συνδυασμό με τις αντίστοιχες μεταγραφές τους.

Συστάσεις προϊόντος
Αναπτύξτε μοντέλα χρησιμοποιώντας εκτεταμένα σύνολα δεδομένων ιστορικών αγορών πελατών, συμπεριλαμβανομένων ετικετών που επισημαίνουν τα προϊόντα που τείνουν να αγοράσουν οι πελάτες. Ο στόχος είναι να παρέχονται ακριβείς προτάσεις στους πελάτες, ενισχύοντας έτσι τις πωλήσεις και ενισχύοντας την ικανοποίηση των πελατών.
Λεζάντα εικόνας
Κάντε επανάσταση στη διαδικασία ερμηνείας της εικόνας σας με την υπερσύγχρονη υπηρεσία Image Captioning με τεχνητή νοημοσύνη. Δίνουμε ζωντάνια στις εικόνες δημιουργώντας ακριβείς και ουσιαστικές περιγραφές με νόημα. Αυτό ανοίγει το δρόμο για καινοτόμες δυνατότητες αφοσίωσης και αλληλεπίδρασης με το οπτικό σας περιεχόμενο για το κοινό σας.

Υπηρεσίες Εκπαίδευσης Κειμένου σε Ομιλία
Παρέχουμε ένα εκτεταμένο σύνολο δεδομένων που αποτελείται από ηχογραφήσεις ανθρώπινης ομιλίας, ιδανικό για την εκπαίδευση μοντέλων AI. Αυτά τα μοντέλα είναι σε θέση να παράγουν φυσικές και ελκυστικές φωνές για τις εφαρμογές σας, προσφέροντας έτσι μια ξεχωριστή και καθηλωτική εμπειρία ήχου στους χρήστες σας.



