
Εκτιμάται ότι κατά μέσο όρο οι ενήλικες λαμβάνουν αποφάσεις για τη ζωή και τα καθημερινά πράγματα με βάση την προηγούμενη μάθηση. Αυτά με τη σειρά τους προέρχονται από εμπειρίες ζωής που διαμορφώνονται από καταστάσεις και ανθρώπους. Με την κυριολεκτική έννοια, οι καταστάσεις, οι περιπτώσεις και οι άνθρωποι δεν είναι παρά δεδομένα που τροφοδοτούνται στο μυαλό μας. Καθώς συγκεντρώνουμε δεδομένα ετών με τη μορφή εμπειρίας, το ανθρώπινο μυαλό τείνει να παίρνει απρόσκοπτες αποφάσεις.
Τι μεταφέρει αυτό; Αυτά τα δεδομένα είναι αναπόφευκτα στη μάθηση.
Παρόμοια με το πώς ένα παιδί χρειάζεται μια ετικέτα που ονομάζεται αλφάβητο για να κατανοήσει τα γράμματα A, B, C, D, ένα μηχάνημα χρειάζεται επίσης να κατανοήσει τα δεδομένα που λαμβάνει.
Αυτό ακριβώς είναι Τεχνητή Νοημοσύνη (AI) η εκπαίδευση είναι το παν. Μια μηχανή δεν διαφέρει από ένα παιδί που δεν έχει μάθει ακόμα πράγματα από αυτά που πρόκειται να διδαχθεί. Το μηχάνημα δεν ξέρει να κάνει διάκριση μεταξύ μιας γάτας και ενός σκύλου ή ενός λεωφορείου και ενός αυτοκινήτου, επειδή δεν έχουν ακόμη δοκιμάσει αυτά τα αντικείμενα ή δεν έχουν μάθει πώς μοιάζουν.
Έτσι, για κάποιον που κατασκευάζει ένα αυτοοδηγούμενο αυτοκίνητο, η κύρια λειτουργία που πρέπει να προστεθεί είναι η ικανότητα του συστήματος να κατανοεί όλα τα καθημερινά στοιχεία που μπορεί να συναντήσει το αυτοκίνητο, ώστε το όχημα να τα αναγνωρίζει και να παίρνει τις κατάλληλες αποφάσεις οδήγησης. Εδώ είναι που Δεδομένα εκπαίδευσης AI μπαίνει στο παιχνίδι.
Σήμερα, οι μονάδες τεχνητής νοημοσύνης μας προσφέρουν πολλές ανέσεις με τη μορφή μηχανών συστάσεων, πλοήγησης, αυτοματισμού και πολλά άλλα. Όλα αυτά συμβαίνουν λόγω της εκπαίδευσης δεδομένων AI που χρησιμοποιήθηκε για την εκπαίδευση των αλγορίθμων ενώ κατασκευάζονταν.
Τα δεδομένα εκπαίδευσης AI είναι μια θεμελιώδης διαδικασία στη δημιουργία μάθηση μηχανής και αλγόριθμους AI. Εάν αναπτύσσετε μια εφαρμογή που βασίζεται σε αυτές τις τεχνολογικές έννοιες, πρέπει να εκπαιδεύσετε τα συστήματά σας ώστε να κατανοούν στοιχεία δεδομένων για βελτιστοποιημένη επεξεργασία. Χωρίς εκπαίδευση, το μοντέλο AI σας θα είναι αναποτελεσματικό, ελαττωματικό και δυνητικά άσκοπο.
Τι είναι τα δεδομένα εκπαίδευσης AI;
Τα δεδομένα εκπαίδευσης AI είναι προσεκτικά επιμελημένες και καθαρισμένες πληροφορίες που τροφοδοτούνται σε ένα σύστημα για εκπαιδευτικούς σκοπούς. Αυτή η διαδικασία κάνει ή σπάει την επιτυχία ενός μοντέλου AI. Μπορεί να βοηθήσει στην ανάπτυξη της κατανόησης ότι δεν είναι όλα τα τετράποδα σε μια εικόνα σκύλοι ή θα μπορούσε να βοηθήσει ένα μοντέλο να κάνει τη διάκριση μεταξύ θυμωμένων φωνών και χαρούμενων γέλιων. Είναι το πρώτο στάδιο στη δημιουργία μονάδων τεχνητής νοημοσύνης που απαιτούν δεδομένα τροφοδοσίας με κουτάλι για να διδάξουν στις μηχανές τα βασικά και να τους επιτρέψουν να μάθουν καθώς τροφοδοτούνται περισσότερα δεδομένα. Αυτό, πάλι, ανοίγει τον δρόμο για μια αποτελεσματική ενότητα που παρέχει ακριβή αποτελέσματα στους τελικούς χρήστες.

Εξετάστε μια διαδικασία δεδομένων εκπαίδευσης τεχνητής νοημοσύνης ως μια συνεδρία εξάσκησης για έναν μουσικό, όπου όσο περισσότερο εξασκούνται, τόσο καλύτερα γίνονται σε ένα τραγούδι ή μια κλίμακα. Η μόνη διαφορά εδώ είναι ότι οι μηχανές πρέπει επίσης πρώτα να διδαχθούν τι είναι ένα μουσικό όργανο. Παρόμοια με τον μουσικό που κάνει καλή χρήση των αμέτρητων ωρών που αφιερώνει στην εξάσκηση στη σκηνή, ένα μοντέλο AI προσφέρει μια βέλτιστη εμπειρία στους καταναλωτές όταν αναπτύσσεται.

Τι είδη δεδομένων χρειάζομαι;
Υπάρχουν 4 βασικοί τύποι δεδομένων που θα χρειαστούν, π.χ., εικόνα, βίντεο, ήχος/ομιλία ή κείμενο για την αποτελεσματική εκπαίδευση μοντέλων μηχανικής εκμάθησης. Ο τύπος των δεδομένων που απαιτούνται θα εξαρτηθεί από μια ποικιλία παραγόντων, όπως η περίπτωση χρήσης, η πολυπλοκότητα των μοντέλων που θα εκπαιδευτούν, η μέθοδος εκπαίδευσης που χρησιμοποιείται και η ποικιλία των απαιτούμενων δεδομένων εισόδου.
Πόσα δεδομένα είναι επαρκή;
Λένε ότι δεν υπάρχει τέλος στη μάθηση και αυτή η φράση είναι ιδανική στο φάσμα δεδομένων εκπαίδευσης AI. Όσο περισσότερα τα δεδομένα, τόσο καλύτερα τα αποτελέσματα. Ωστόσο, μια τόσο ασαφής απάντηση δεν αρκεί για να πείσει οποιονδήποτε θέλει να ξεκινήσει μια εφαρμογή με τεχνητή νοημοσύνη. Αλλά η πραγματικότητα είναι ότι δεν υπάρχει γενικός εμπειρικός κανόνας, ένας τύπος, ένας δείκτης ή μια μέτρηση του ακριβούς όγκου δεδομένων που χρειάζεται κάποιος για να εκπαιδεύσει τα σύνολα δεδομένων AI του.

Ένας εμπειρογνώμονας μηχανικής μάθησης θα αποκάλυπτε κωμικά ότι ένας ξεχωριστός αλγόριθμος ή ενότητα πρέπει να κατασκευαστεί για να συμπεράνει τον όγκο των δεδομένων που απαιτούνται για ένα έργο. Αυτή είναι δυστυχώς και η πραγματικότητα.
Τώρα, υπάρχει ένας λόγος για τον οποίο είναι εξαιρετικά δύσκολο να τεθεί ένα όριο στον όγκο των δεδομένων που απαιτούνται για την εκπαίδευση AI. Αυτό οφείλεται στις πολυπλοκότητες που περιλαμβάνει η ίδια η εκπαιδευτική διαδικασία. Μια μονάδα τεχνητής νοημοσύνης περιλαμβάνει πολλά επίπεδα διασυνδεδεμένων και επικαλυπτόμενων τμημάτων που επηρεάζουν και συμπληρώνουν το ένα τις διαδικασίες του άλλου.
Για παράδειγμα, ας θεωρήσουμε ότι αναπτύσσετε μια απλή εφαρμογή για την αναγνώριση ενός δέντρου καρύδας. Από την άποψη, ακούγεται μάλλον απλό, σωστά; Από την άποψη της τεχνητής νοημοσύνης, ωστόσο, είναι πολύ πιο περίπλοκο.
Στην αρχή, το μηχάνημα είναι άδειο. Δεν γνωρίζει αρχικά τι είναι δέντρο, πόσο μάλλον ένα ψηλό, τροπικό δέντρο που καρποφορεί ειδικά για την περιοχή. Για αυτό, το μοντέλο πρέπει να εκπαιδευτεί στο τι είναι ένα δέντρο, πώς να διαφοροποιεί από άλλα ψηλά και λεπτά αντικείμενα που μπορεί να εμφανίζονται στο πλαίσιο, όπως φώτα δρόμους ή ηλεκτρικούς στύλους και στη συνέχεια να του διδάξει τις αποχρώσεις ενός δέντρου καρύδας. Μόλις η ενότητα μηχανικής εκμάθησης μάθει τι είναι ένα δέντρο καρύδας, θα μπορούσε κανείς με ασφάλεια να υποθέσει ότι ξέρει πώς να το αναγνωρίσει.
Αλλά μόνο όταν τροφοδοτείτε μια εικόνα ενός δέντρου μπανγιάν, θα συνειδητοποιήσετε ότι το σύστημα έχει λανθασμένα προσδιορίσει ένα δέντρο μπανιάν για δέντρο καρύδας. Για ένα σύστημα, οτιδήποτε είναι ψηλό με συγκεντρωμένο φύλλωμα είναι δέντρο καρύδας. Για να εξαλειφθεί αυτό, το σύστημα πρέπει τώρα να κατανοήσει κάθε δέντρο που δεν είναι δέντρο καρύδας για να προσδιορίσει με ακρίβεια. Εάν αυτή είναι η διαδικασία για μια απλή εφαρμογή μονής κατεύθυνσης με ένα μόνο αποτέλεσμα, μπορούμε μόνο να φανταστούμε τις πολυπλοκότητες που εμπλέκονται σε εφαρμογές που αναπτύσσονται για την υγειονομική περίθαλψη, τα οικονομικά και άλλα.



Πώς βελτιώνετε την Ποιότητα Δεδομένων;
Η ποιότητα των δεδομένων είναι ευθέως ανάλογη με την ποιότητα της παραγωγής. Γι' αυτό τα μοντέλα υψηλής ακρίβειας απαιτούν σύνολα δεδομένων υψηλής ποιότητας για εκπαίδευση. Ωστόσο, υπάρχει μια σύλληψη. Για μια έννοια που βασίζεται στην ακρίβεια και την ακρίβεια, η έννοια της ποιότητας είναι συχνά μάλλον ασαφής.
Τα δεδομένα υψηλής ποιότητας ακούγονται δυνατά και αξιόπιστα, αλλά τι σημαίνουν στην πραγματικότητα;
Τι είναι η ποιότητα καταρχήν;
Λοιπόν, όπως τα ίδια τα δεδομένα που τροφοδοτούμε στα συστήματά μας, η ποιότητα έχει επίσης πολλούς παράγοντες και παραμέτρους που σχετίζονται με αυτήν. Εάν απευθυνθείτε σε ειδικούς της τεχνητής νοημοσύνης ή με βετεράνους μηχανικής μάθησης, μπορεί να μοιραστούν οποιαδήποτε μετάθεση δεδομένων υψηλής ποιότητας είναι οτιδήποτε είναι -

- Στολή – δεδομένα που προέρχονται από μια συγκεκριμένη πηγή ή ομοιομορφία σε σύνολα δεδομένων που προέρχονται από πολλαπλές πηγές
- Περιεκτική – δεδομένα που καλύπτουν όλα τα πιθανά σενάρια στα οποία πρόκειται να λειτουργήσει το σύστημά σας
- Συνεπής – κάθε byte δεδομένων είναι παρόμοιας φύσης
- Σχετικό – τα δεδομένα που προμηθεύετε και τροφοδοτείτε είναι παρόμοια με τις απαιτήσεις και τα αναμενόμενα αποτελέσματα και
- Διάφορα – έχετε έναν συνδυασμό όλων των τύπων δεδομένων όπως ήχου, βίντεο, εικόνας, κειμένου και άλλα
Τώρα που καταλαβαίνουμε τι σημαίνει ποιότητα στην ποιότητα δεδομένων, ας δούμε γρήγορα τους διαφορετικούς τρόπους με τους οποίους θα μπορούσαμε να διασφαλίσουμε την ποιότητα συλλογή δεδομένων και γενιά.
Τι επηρεάζει την ποιότητα των δεδομένων εκπαίδευσης;
Υπάρχουν τρεις κύριοι παράγοντες που μπορούν να σας βοηθήσουν να προβλέψετε το επίπεδο ποιότητας που επιθυμείτε για τα μοντέλα AI/ML. Οι 3 βασικοί παράγοντες είναι οι άνθρωποι, η διαδικασία και η πλατφόρμα που μπορούν να δημιουργήσουν ή να καταστρέψουν το Έργο AI σας.
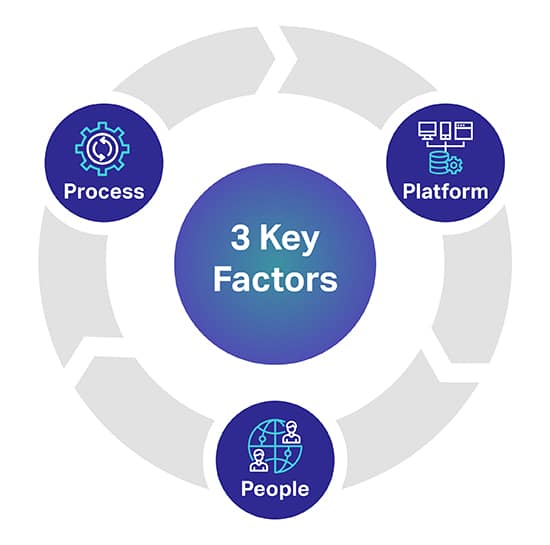
Πλατφόρμα: Απαιτείται μια πλήρης ιδιόκτητη πλατφόρμα ανθρώπινου δυναμικού για την προέλευση, τη μεταγραφή και τον σχολιασμό διαφόρων συνόλων δεδομένων για την επιτυχή ανάπτυξη των πιο απαιτητικών πρωτοβουλιών AI και ML. Η πλατφόρμα είναι επίσης υπεύθυνη για τη διαχείριση των εργαζομένων και τη μεγιστοποίηση της ποιότητας και της απόδοσης
άνθρωποι: Για να κάνει την τεχνητή νοημοσύνη να σκέφτεται εξυπνότερα χρειάζονται άνθρωποι που είναι μερικά από τα πιο έξυπνα μυαλά στον κλάδο. Για να κλιμακώσετε, χρειάζεστε χιλιάδες από αυτούς τους επαγγελματίες σε όλο τον κόσμο για να μεταγράψουν, να επισημάνουν και να σχολιάσουν όλους τους τύπους δεδομένων.
Διαδικασία: Η παροχή δεδομένων χρυσού προτύπου που είναι συνεπή, πλήρη και ακριβή είναι πολύπλοκη δουλειά. Αλλά είναι αυτό που θα πρέπει πάντα να παρέχετε, ώστε να τηρείτε τα υψηλότερα πρότυπα ποιότητας, καθώς και αυστηρούς και αποδεδειγμένους ποιοτικούς ελέγχους και σημεία ελέγχου.
Από πού προμηθεύεστε δεδομένα εκπαίδευσης AI;
Σε αντίθεση με την προηγούμενη ενότητα, έχουμε μια πολύ ακριβή εικόνα εδώ. Για όσους από εσάς αναζητούν πηγή δεδομένων
ή αν βρίσκεστε στη διαδικασία συλλογής βίντεο, συλλογής εικόνων, συλλογής κειμένου και άλλων, υπάρχουν τρία
πρωταρχικές οδούς από τις οποίες μπορείτε να προμηθεύεστε τα δεδομένα σας.
Ας τα εξερευνήσουμε ξεχωριστά.
Δωρεάν πηγές
Οι δωρεάν πηγές είναι λεωφόροι που είναι ακούσιες αποθήκες τεράστιων όγκων δεδομένων. Είναι δεδομένα που απλά βρίσκονται εκεί στην επιφάνεια δωρεάν. Μερικοί από τους δωρεάν πόρους περιλαμβάνουν -

- Σύνολα δεδομένων της Google, όπου κυκλοφόρησαν πάνω από 250 εκατομμύρια σύνολα δεδομένων το 2020
- Φόρουμ όπως το Reddit, το Quora και άλλα, τα οποία αποτελούν ευρηματικές πηγές δεδομένων. Επιπλέον, η επιστήμη δεδομένων και οι κοινότητες τεχνητής νοημοσύνης σε αυτά τα φόρουμ θα μπορούσαν επίσης να σας βοηθήσουν με συγκεκριμένα σύνολα δεδομένων όταν επικοινωνήσετε.
- Το Kaggle είναι μια άλλη δωρεάν πηγή όπου μπορείτε να βρείτε πόρους μηχανικής εκμάθησης εκτός από δωρεάν σύνολα δεδομένων.
- Έχουμε επίσης παραθέσει δωρεάν ανοιχτά σύνολα δεδομένων για να ξεκινήσετε με την εκπαίδευση των μοντέλων σας AI
Αν και αυτοί οι δρόμοι είναι δωρεάν, αυτό που θα καταλήξετε να ξοδέψετε είναι χρόνος και προσπάθεια. Δεδομένα από δωρεάν πηγές είναι παντού και πρέπει να καταβάλετε ώρες εργασίας για να τα προμηθευτείτε, να τα καθαρίσετε και να τα προσαρμόσετε ανάλογα με τις ανάγκες σας.
Ένα από τα άλλα σημαντικά σημεία που πρέπει να θυμάστε είναι ότι ορισμένα από τα δεδομένα από δωρεάν πηγές δεν μπορούν να χρησιμοποιηθούν και για εμπορικούς σκοπούς. Απαιτεί αδειοδότηση δεδομένων.
Άνοιγμα συνόλων δεδομένων – Να χρησιμοποιηθούν ή να μην χρησιμοποιηθούν;
 Τα ανοιχτά σύνολα δεδομένων είναι δημόσια διαθέσιμα σύνολα δεδομένων που μπορούν να χρησιμοποιηθούν για έργα μηχανικής εκμάθησης. Δεν έχει σημασία αν χρειάζεστε σύνολο δεδομένων ήχου, βίντεο, εικόνας ή κειμένου, υπάρχουν ανοιχτά σύνολα δεδομένων διαθέσιμα για όλες τις μορφές και τις κατηγορίες δεδομένων.
Τα ανοιχτά σύνολα δεδομένων είναι δημόσια διαθέσιμα σύνολα δεδομένων που μπορούν να χρησιμοποιηθούν για έργα μηχανικής εκμάθησης. Δεν έχει σημασία αν χρειάζεστε σύνολο δεδομένων ήχου, βίντεο, εικόνας ή κειμένου, υπάρχουν ανοιχτά σύνολα δεδομένων διαθέσιμα για όλες τις μορφές και τις κατηγορίες δεδομένων.
Για παράδειγμα, υπάρχει το σύνολο δεδομένων κριτικών προϊόντων της Amazon που περιλαμβάνει πάνω από 142 εκατομμύρια κριτικές χρηστών από το 1996 έως το 2014. Για τις εικόνες, έχετε έναν εξαιρετικό πόρο όπως το Google Open Images, όπου μπορείτε να προμηθεύσετε σύνολα δεδομένων από περισσότερες από 9 εκατομμύρια φωτογραφίες. Η Google διαθέτει επίσης μια πτέρυγα που ονομάζεται Machine Perception που προσφέρει σχεδόν 2 εκατομμύρια ηχητικά κλιπ διάρκειας δέκα δευτερολέπτων.
Παρά τη διαθεσιμότητα αυτών των πόρων (και άλλων), ο σημαντικός παράγοντας που συχνά παραβλέπεται είναι οι συνθήκες που συνοδεύουν τη χρήση τους. Είναι σίγουρα δημόσια, αλλά υπάρχει μια λεπτή γραμμή μεταξύ παραβίασης και ορθής χρήσης. Κάθε πόρος συνοδεύεται από τη δική του κατάσταση και εάν εξερευνάτε αυτές τις επιλογές, σας προτείνουμε να είστε προσεκτικοί. Αυτό συμβαίνει γιατί με το πρόσχημα της προτίμησης των ελεύθερων λεωφόρων, θα μπορούσατε να καταλήξετε να υποστείτε αγωγές και συμμαχικά έξοδα.
Το πραγματικό κόστος των δεδομένων εκπαίδευσης AI
Μόνο τα χρήματα που ξοδεύετε για την απόκτηση δεδομένων ή τη δημιουργία δεδομένων στο εσωτερικό δεν είναι αυτό που πρέπει να λάβετε υπόψη. Πρέπει να εξετάσουμε γραμμικά στοιχεία όπως ο χρόνος και οι προσπάθειες που δαπανώνται για την ανάπτυξη συστημάτων τεχνητής νοημοσύνης και κόστος από συναλλακτική σκοπιά. αποτυγχάνει να επαινέσει τον άλλον.
Χρόνος που δαπανάται για την προμήθεια και τον σχολιασμό δεδομένων
Παράγοντες όπως η γεωγραφία, τα δημογραφικά στοιχεία της αγοράς και ο ανταγωνισμός εντός της θέσης σας εμποδίζουν τη διαθεσιμότητα των σχετικών συνόλων δεδομένων. Ο χρόνος που αφιερώνεται στη μη αυτόματη αναζήτηση δεδομένων είναι σπατάλη χρόνου για την εκπαίδευση του συστήματος AI σας. Μόλις καταφέρετε να προμηθεύσετε τα δεδομένα σας, θα καθυστερήσετε περαιτέρω την εκπαίδευση αφιερώνοντας χρόνο στον σχολιασμό των δεδομένων, ώστε το μηχάνημά σας να καταλάβει τι τροφοδοτείται.
Η τιμή συλλογής και σχολιασμού δεδομένων
Τα γενικά έξοδα (εσωτερικοί συλλέκτες δεδομένων, σχολιαστές, συντήρηση εξοπλισμού, υποδομή τεχνολογίας, συνδρομές σε εργαλεία SaaS, ανάπτυξη αποκλειστικών εφαρμογών) απαιτείται να υπολογίζονται κατά την προμήθεια δεδομένων τεχνητής νοημοσύνης
Το κόστος των κακών δεδομένων
Τα κακά δεδομένα μπορεί να κοστίσουν το ηθικό της ομάδας της εταιρείας σας, το ανταγωνιστικό σας πλεονέκτημα και άλλες απτές συνέπειες που περνούν απαρατήρητες. Ορίζουμε κακά δεδομένα ως οποιοδήποτε σύνολο δεδομένων που είναι ακάθαρτο, ακατέργαστο, άσχετο, ξεπερασμένο, ανακριβές ή γεμάτο ορθογραφικά λάθη. Τα κακά δεδομένα μπορούν να χαλάσουν το μοντέλο τεχνητής νοημοσύνης εισάγοντας μεροληψία και καταστρέφοντας τους αλγόριθμούς σας με λοξά αποτελέσματα.
Έξοδα Διαχείρισης
Όλα τα κόστη που αφορούν τη διαχείριση του οργανισμού ή της επιχείρησής σας, τα υλικά και τα άυλα στοιχεία αποτελούν έξοδα διαχείρισης που είναι συχνά τα πιο ακριβά.

Τι ακολουθεί μετά την Προέλευση δεδομένων;
Μόλις έχετε το σύνολο δεδομένων στα χέρια σας, το επόμενο βήμα είναι να το σχολιάσετε ή να το επισημάνετε. Μετά από όλες τις περίπλοκες εργασίες, αυτό που έχετε είναι καθαρά ακατέργαστα δεδομένα. Το μηχάνημα εξακολουθεί να μην μπορεί να κατανοήσει τα δεδομένα που έχετε επειδή δεν σχολιάζονται. Εδώ ξεκινά το υπόλοιπο μέρος της πραγματικής πρόκλησης.
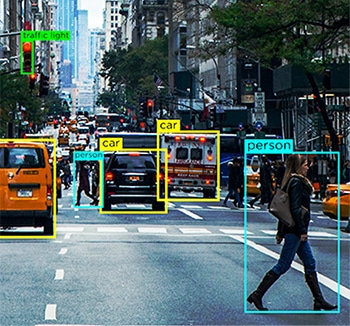
Όπως αναφέραμε, ένα μηχάνημα χρειάζεται δεδομένα σε μορφή που μπορεί να κατανοήσει. Αυτό ακριβώς κάνει ο σχολιασμός δεδομένων. Παίρνει ακατέργαστα δεδομένα και προσθέτει επίπεδα ετικετών και ετικετών για να βοηθήσει μια μονάδα να κατανοήσει κάθε στοιχείο στα δεδομένα με ακρίβεια.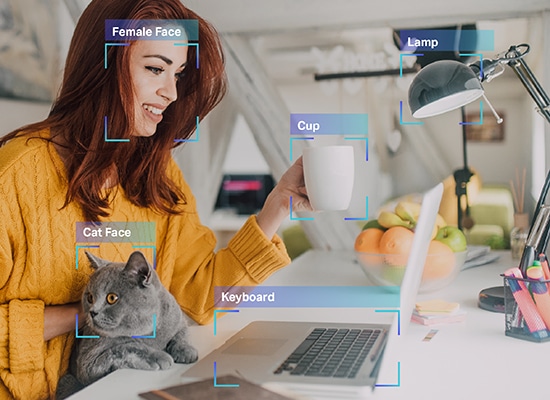
Για παράδειγμα, σε ένα κείμενο, η επισήμανση δεδομένων θα πει σε ένα σύστημα AI τη γραμματική σύνταξη, τα μέρη του λόγου, τις προθέσεις, τα σημεία στίξης, το συναίσθημα, το συναίσθημα και άλλες παραμέτρους που εμπλέκονται στη μηχανική κατανόηση. Αυτός είναι ο τρόπος με τον οποίο τα chatbot κατανοούν καλύτερα τις ανθρώπινες συνομιλίες και μόνο όταν το κάνουν μπορούν να μιμηθούν καλύτερα τις ανθρώπινες αλληλεπιδράσεις μέσω των απαντήσεών τους επίσης.
Όσο αναπόφευκτο κι αν ακούγεται, είναι επίσης εξαιρετικά χρονοβόρο και κουραστικό. Ανεξάρτητα από την κλίμακα της επιχείρησής σας ή τις φιλοδοξίες της, ο χρόνος που απαιτείται για τον σχολιασμό των δεδομένων είναι τεράστιος.
Αυτό συμβαίνει κυρίως επειδή το υπάρχον εργατικό δυναμικό σας πρέπει να αφιερώσει χρόνο εκτός του καθημερινού του προγράμματος για να σχολιάσει δεδομένα, εάν δεν έχετε ειδικούς σχολιασμού δεδομένων. Επομένως, πρέπει να καλέσετε τα μέλη της ομάδας σας και να το αναθέσετε ως πρόσθετη εργασία. Όσο περισσότερο καθυστερεί, τόσο περισσότερος χρόνος χρειάζεται για να εκπαιδεύσετε τα μοντέλα AI σας.
Αν και υπάρχουν δωρεάν εργαλεία για σχολιασμό δεδομένων, αυτό δεν αφαιρεί το γεγονός ότι αυτή η διαδικασία είναι χρονοβόρα.
Εκεί έρχονται οι προμηθευτές σχολιασμών δεδομένων όπως η Shaip. Φέρνουν μαζί τους μια ειδική ομάδα ειδικών σχολιασμού δεδομένων για να επικεντρωθούν μόνο στο έργο σας. Σας προσφέρουν λύσεις με τον τρόπο που θέλετε για τις ανάγκες και τις απαιτήσεις σας. Επιπλέον, μπορείτε να ορίσετε ένα χρονοδιάγραμμα μαζί τους και να ζητήσετε να ολοκληρωθούν οι εργασίες σε αυτό το συγκεκριμένο χρονοδιάγραμμα.
Ένα από τα σημαντικότερα πλεονεκτήματα είναι το γεγονός ότι τα μέλη της ομάδας σας μπορούν να συνεχίσουν να εστιάζουν σε ό,τι έχει μεγαλύτερη σημασία για τις λειτουργίες και το έργο σας, ενώ οι ειδικοί κάνουν τη δουλειά τους να σχολιάζουν και να επισημαίνουν δεδομένα για εσάς.
Με την εξωτερική ανάθεση, μπορεί να εξασφαλιστεί η βέλτιστη ποιότητα, ο ελάχιστος χρόνος και η μέγιστη ακρίβεια.