
Η Τεχνητή Νοημοσύνη και τα Μεγάλα Δεδομένα έχουν τη δυνατότητα να βρουν λύσεις σε παγκόσμια προβλήματα, δίνοντας παράλληλα προτεραιότητα σε τοπικά ζητήματα και μεταμορφώνοντας τον κόσμο με πολλούς τρόπους. Η τεχνητή νοημοσύνη φέρνει λύσεις σε όλους – και σε όλες τις ρυθμίσεις, από το σπίτι μέχρι τους χώρους εργασίας. υπολογιστές AI, με Μηχανική μάθηση εκπαίδευση, μπορεί να προσομοιώσει έξυπνη συμπεριφορά και συνομιλίες με αυτοματοποιημένο αλλά εξατομικευμένο τρόπο.
Ωστόσο, η τεχνητή νοημοσύνη αντιμετωπίζει ένα πρόβλημα συμπερίληψης και είναι συχνά προκατειλημμένη. Ευτυχώς, εστιάζοντας σε ηθική της τεχνητής νοημοσύνης μπορεί να εισάγει νεότερες δυνατότητες όσον αφορά τη διαφοροποίηση και την ένταξη εξαλείφοντας την ασυνείδητη προκατάληψη μέσω διαφορετικών δεδομένων εκπαίδευσης.
Σημασία της διαφορετικότητας στα δεδομένα εκπαίδευσης AI
 Η ποικιλομορφία και η ποιότητα των δεδομένων εκπαίδευσης σχετίζονται, καθώς το ένα επηρεάζει το άλλο και επηρεάζει το αποτέλεσμα της λύσης AI. Η επιτυχία της λύσης AI εξαρτάται από το ποικίλα δεδομένα εκπαιδεύεται σε. Η ποικιλομορφία δεδομένων εμποδίζει την υπερπροσαρμογή του AI – που σημαίνει ότι το μοντέλο αποδίδει ή μαθαίνει μόνο από τα δεδομένα που χρησιμοποιούνται για την εκπαίδευση. Με την υπερπροσαρμογή, το μοντέλο AI δεν μπορεί να παράσχει αποτελέσματα όταν δοκιμάζεται σε δεδομένα που δεν χρησιμοποιούνται στην εκπαίδευση.
Η ποικιλομορφία και η ποιότητα των δεδομένων εκπαίδευσης σχετίζονται, καθώς το ένα επηρεάζει το άλλο και επηρεάζει το αποτέλεσμα της λύσης AI. Η επιτυχία της λύσης AI εξαρτάται από το ποικίλα δεδομένα εκπαιδεύεται σε. Η ποικιλομορφία δεδομένων εμποδίζει την υπερπροσαρμογή του AI – που σημαίνει ότι το μοντέλο αποδίδει ή μαθαίνει μόνο από τα δεδομένα που χρησιμοποιούνται για την εκπαίδευση. Με την υπερπροσαρμογή, το μοντέλο AI δεν μπορεί να παράσχει αποτελέσματα όταν δοκιμάζεται σε δεδομένα που δεν χρησιμοποιούνται στην εκπαίδευση.
Η τρέχουσα κατάσταση της εκπαίδευσης στην τεχνητή νοημοσύνη ημερομηνία
Η ανισότητα ή η έλλειψη διαφορετικότητας στα δεδομένα θα οδηγούσε σε άδικες, ανήθικες και μη περιεκτικές λύσεις τεχνητής νοημοσύνης που θα μπορούσαν να εμβαθύνουν τις διακρίσεις. Αλλά πώς και γιατί η ποικιλομορφία στα δεδομένα σχετίζεται με λύσεις τεχνητής νοημοσύνης;
Η άνιση εκπροσώπηση όλων των τάξεων οδηγεί σε εσφαλμένη αναγνώριση των προσώπων – μια σημαντική περίπτωση είναι το Google Photos που ταξινόμησε ένα μαύρο ζευγάρι ως «γορίλες». Και το Meta ζητά από έναν χρήστη που παρακολουθεί ένα βίντεο με μαύρους άνδρες εάν ο χρήστης θα ήθελε «να συνεχίσει να παρακολουθεί βίντεο με πρωτεύοντα θηλαστικά».
Για παράδειγμα, η ανακριβής ή ακατάλληλη ταξινόμηση των εθνικών ή φυλετικών μειονοτήτων, ειδικά στα chatbots, θα μπορούσε να οδηγήσει σε προκατάληψη στα συστήματα εκπαίδευσης τεχνητής νοημοσύνης. Σύμφωνα με την έκθεση του 2019 για Συστήματα διάκρισης – Φύλο, Φυλή, Ισχύς στο AI, περισσότερο από το 80% των δασκάλων της AI είναι άνδρες. Οι γυναίκες ερευνήτριες τεχνητής νοημοσύνης στο FB αποτελούν μόνο το 15% και το 10% στη Google.
Ο αντίκτυπος των διαφορετικών δεδομένων εκπαίδευσης στην απόδοση της τεχνητής νοημοσύνης
 Η απομάκρυνση συγκεκριμένων ομάδων και κοινοτήτων από την αναπαράσταση δεδομένων μπορεί να οδηγήσει σε λοξούς αλγόριθμους.
Η απομάκρυνση συγκεκριμένων ομάδων και κοινοτήτων από την αναπαράσταση δεδομένων μπορεί να οδηγήσει σε λοξούς αλγόριθμους.
Η μεροληψία δεδομένων συχνά εισάγεται κατά λάθος στα συστήματα δεδομένων – με υποδειγματοληψία ορισμένων φυλών ή ομάδων. Όταν τα συστήματα αναγνώρισης προσώπου εκπαιδεύονται σε διαφορετικά πρόσωπα, βοηθά το μοντέλο να αναγνωρίσει συγκεκριμένα χαρακτηριστικά, όπως η θέση των οργάνων του προσώπου και οι χρωματικές παραλλαγές.
Ένα άλλο αποτέλεσμα της ύπαρξης μη ισορροπημένης συχνότητας ετικετών είναι ότι το σύστημα μπορεί να θεωρήσει μια μειοψηφία ως ανωμαλία όταν πιέζεται για να παράγει μια έξοδο σε σύντομο χρονικό διάστημα.
Επίτευξη Ποικιλομορφίας στα Εκπαιδευτικά Δεδομένα AI
Από την άλλη πλευρά, η δημιουργία διαφορετικών δεδομένων είναι επίσης μια πρόκληση. Η απόλυτη έλλειψη δεδομένων για ορισμένες κατηγορίες θα μπορούσε να οδηγήσει σε υποεκπροσώπηση. Μπορεί να μετριαστεί κάνοντας τις ομάδες προγραμματιστών AI πιο διαφορετικές όσον αφορά τις δεξιότητες, την εθνικότητα, τη φυλή, το φύλο, την πειθαρχία και πολλά άλλα. Επιπλέον, ο ιδανικός τρόπος αντιμετώπισης προβλημάτων διαφοροποίησης δεδομένων στην τεχνητή νοημοσύνη είναι να το αντιμετωπίσετε από τη λέξη go αντί να προσπαθήσετε να διορθώσετε αυτό που έχει γίνει – εμφυσώντας ποικιλομορφία στο στάδιο της συλλογής και επιμέλειας δεδομένων.
Ανεξάρτητα από τη διαφημιστική εκστρατεία γύρω από την τεχνητή νοημοσύνη, εξακολουθεί να εξαρτάται από τα δεδομένα που συλλέγονται, επιλέγονται και εκπαιδεύονται από τους ανθρώπους. Η έμφυτη προκατάληψη στους ανθρώπους θα αντικατοπτρίζεται στα δεδομένα που συλλέγονται από αυτούς και αυτή η ασυνείδητη προκατάληψη εισχωρεί και στα μοντέλα ML.
Βήματα για τη συλλογή και την επιμέλεια διαφορετικών δεδομένων εκπαίδευσης
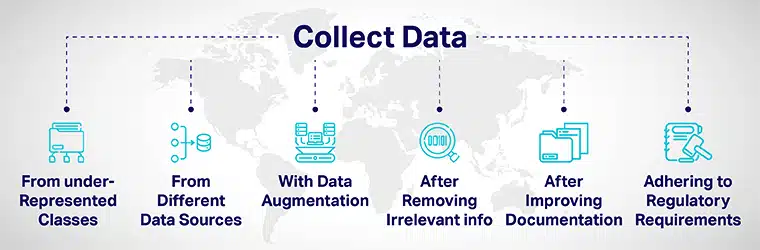
Ποικιλομορφία δεδομένων μπορεί να επιτευχθεί με:
- Προσθέστε προσεκτικά περισσότερα δεδομένα από υποεκπροσωπούμενες κατηγορίες και εκθέστε τα μοντέλα σας σε διάφορα σημεία δεδομένων.
- Με τη συλλογή δεδομένων από διαφορετικές πηγές δεδομένων.
- Με αύξηση δεδομένων ή τεχνητό χειρισμό συνόλων δεδομένων για την αύξηση/συμπερίληψη νέων σημείων δεδομένων σαφώς διαφορετικών από τα αρχικά σημεία δεδομένων.
- Κατά την πρόσληψη αιτούντων για τη διαδικασία ανάπτυξης τεχνητής νοημοσύνης, αφαιρέστε όλες τις πληροφορίες που δεν σχετίζονται με την εργασία από την εφαρμογή.
- Βελτίωση της διαφάνειας και της λογοδοσίας μέσω της βελτίωσης της τεκμηρίωσης της ανάπτυξης και της αξιολόγησης μοντέλων.
- Εισαγωγή κανονισμών για τη δημιουργία διαφορετικότητας και ενσωμάτωση στην τεχνητή νοημοσύνη συστήματα από το επίπεδο της βάσης. Διάφορες κυβερνήσεις έχουν αναπτύξει κατευθυντήριες γραμμές για να διασφαλίσουν την ποικιλομορφία και να μετριάσουν την προκατάληψη της τεχνητής νοημοσύνης που μπορεί να αποφέρει άδικα αποτελέσματα.
[ Διαβάστε επίσης: Μάθετε περισσότερα σχετικά με τη διαδικασία συλλογής δεδομένων εκπαίδευσης AI ]
Συμπέρασμα
Επί του παρόντος, μόνο μερικές μεγάλες εταιρείες τεχνολογίας και κέντρα εκμάθησης ασχολούνται αποκλειστικά με την ανάπτυξη λύσεων τεχνητής νοημοσύνης. Αυτοί οι χώροι της ελίτ είναι βουτηγμένοι στον αποκλεισμό, τις διακρίσεις και την προκατάληψη. Ωστόσο, αυτοί είναι οι χώροι όπου αναπτύσσεται η τεχνητή νοημοσύνη και η λογική πίσω από αυτά τα προηγμένα συστήματα τεχνητής νοημοσύνης είναι γεμάτη με την ίδια προκατάληψη, διακρίσεις και αποκλεισμούς που βαρύνουν τις υποεκπροσωπούμενες ομάδες.
Ενώ συζητάμε για τη διαφορετικότητα και τη μη διάκριση, είναι σημαντικό να αμφισβητούμε τους ανθρώπους που ωφελεί και αυτούς που βλάπτει. Θα πρέπει επίσης να εξετάσουμε ποιον θέτει σε μειονεκτική θέση – επιβάλλοντας την ιδέα ενός «κανονικού» ανθρώπου, η τεχνητή νοημοσύνη θα μπορούσε ενδεχομένως να θέσει σε κίνδυνο τους «άλλους».
Η συζήτηση για την ποικιλομορφία στα δεδομένα της τεχνητής νοημοσύνης χωρίς την αναγνώριση των σχέσεων ισχύος, της ισότητας και της δικαιοσύνης δεν θα δείξει τη μεγαλύτερη εικόνα. Για να κατανοήσουμε πλήρως το εύρος της ποικιλομορφίας στα δεδομένα εκπαίδευσης τεχνητής νοημοσύνης και πώς οι άνθρωποι και η τεχνητή νοημοσύνη μπορούν μαζί να μετριάσουν αυτήν την κρίση, απευθυνθείτε στους μηχανικούς στο Shaip. Έχουμε διαφορετικούς μηχανικούς τεχνητής νοημοσύνης που μπορούν να παρέχουν δυναμικά και διαφορετικά δεδομένα για τις λύσεις τεχνητής νοημοσύνης σας.


