
Η τεχνητή νοημοσύνη, τα μεγάλα δεδομένα και η μηχανική μάθηση συνεχίζουν να επηρεάζουν τους υπεύθυνους χάραξης πολιτικής, τις επιχειρήσεις, την επιστήμη, τους οίκους πολυμέσων και μια ποικιλία βιομηχανιών σε όλο τον κόσμο. Οι αναφορές υποδηλώνουν ότι το παγκόσμιο ποσοστό υιοθέτησης της τεχνητής νοημοσύνης είναι επί του παρόντος στο ίδιο επίπεδο 35% στο 2022 – μια τεράστια αύξηση 4% από το 2021. Ένα επιπλέον 42% των εταιρειών φέρεται να διερευνά τα πολλά οφέλη της τεχνητής νοημοσύνης για την επιχείρησή τους.
Ενισχύοντας τις πολλές πρωτοβουλίες τεχνητής νοημοσύνης και Μηχανική μάθηση οι λύσεις είναι δεδομένα. Η τεχνητή νοημοσύνη μπορεί να είναι τόσο καλή όσο τα δεδομένα που τροφοδοτούν τον αλγόριθμο. Τα δεδομένα χαμηλής ποιότητας θα μπορούσαν να οδηγήσουν σε χαμηλής ποιότητας αποτελέσματα και ανακριβείς προβλέψεις.
Αν και έχει δοθεί μεγάλη προσοχή στην ανάπτυξη λύσεων ML και AI, λείπει η επίγνωση του τι πληροί τις προϋποθέσεις ως σύνολο δεδομένων ποιότητας. Σε αυτό το άρθρο, περιηγούμαστε στο χρονοδιάγραμμα του ποιοτικά δεδομένα εκπαίδευσης AI και να προσδιορίσει το μέλλον της τεχνητής νοημοσύνης μέσω της κατανόησης της συλλογής δεδομένων και της εκπαίδευσης.
Ορισμός δεδομένων εκπαίδευσης AI
Κατά την κατασκευή μιας λύσης ML, σημασία έχει η ποσότητα και η ποιότητα του συνόλου δεδομένων εκπαίδευσης. Το σύστημα ML όχι μόνο απαιτεί μεγάλους όγκους δυναμικών, αμερόληπτων και πολύτιμων δεδομένων εκπαίδευσης, αλλά χρειάζεται επίσης πολλά από αυτά.
Τι είναι όμως τα δεδομένα εκπαίδευσης AI;
Τα δεδομένα εκπαίδευσης AI είναι μια συλλογή δεδομένων με ετικέτα που χρησιμοποιούνται για την εκπαίδευση του αλγόριθμου ML ώστε να κάνει ακριβείς προβλέψεις. Το σύστημα ML προσπαθεί να αναγνωρίσει και να αναγνωρίσει μοτίβα, να κατανοήσει τις σχέσεις μεταξύ των παραμέτρων, να λάβει τις απαραίτητες αποφάσεις και να αξιολογήσει με βάση τα δεδομένα εκπαίδευσης.
Πάρτε το παράδειγμα των αυτοοδηγούμενων αυτοκινήτων, για παράδειγμα. Το σύνολο δεδομένων εκπαίδευσης για ένα μοντέλο ML αυτόνομης οδήγησης θα πρέπει να περιλαμβάνει εικόνες και βίντεο με ετικέτα αυτοκινήτων, πεζών, πινακίδων και άλλων οχημάτων.
Εν ολίγοις, για να βελτιώσετε την ποιότητα του αλγορίθμου ML, χρειάζεστε μεγάλες ποσότητες καλά δομημένων, σχολιασμένων και ετικετοποιημένων δεδομένων εκπαίδευσης.
Σημασία των ποιοτικών δεδομένων εκπαίδευσης και η εξέλιξή τους
Τα δεδομένα εκπαίδευσης υψηλής ποιότητας είναι το βασικό στοιχείο στην ανάπτυξη εφαρμογών AI και ML. Τα δεδομένα συλλέγονται από διάφορες πηγές και παρουσιάζονται σε μη οργανωμένη μορφή ακατάλληλη για σκοπούς μηχανικής εκμάθησης. Τα ποιοτικά δεδομένα εκπαίδευσης – με ετικέτα, σχολιασμό και ετικέτα – είναι πάντα σε οργανωμένη μορφή – ιδανικά για εκπαίδευση ML.
Τα ποιοτικά δεδομένα εκπαίδευσης διευκολύνουν το σύστημα ML να αναγνωρίζει αντικείμενα και να τα ταξινομεί σύμφωνα με προκαθορισμένα χαρακτηριστικά. Το σύνολο δεδομένων θα μπορούσε να αποφέρει κακά αποτελέσματα του μοντέλου εάν η ταξινόμηση δεν είναι ακριβής.
Δεδομένα εκπαίδευσης στις πρώτες ημέρες της AI
Παρά το γεγονός ότι η τεχνητή νοημοσύνη κυριαρχεί στον σημερινό επιχειρηματικό και ερευνητικό κόσμο, οι πρώτες μέρες πριν από την ML κυριαρχούσαν Τεχνητή νοημοσύνη ήταν αρκετά διαφορετικό.
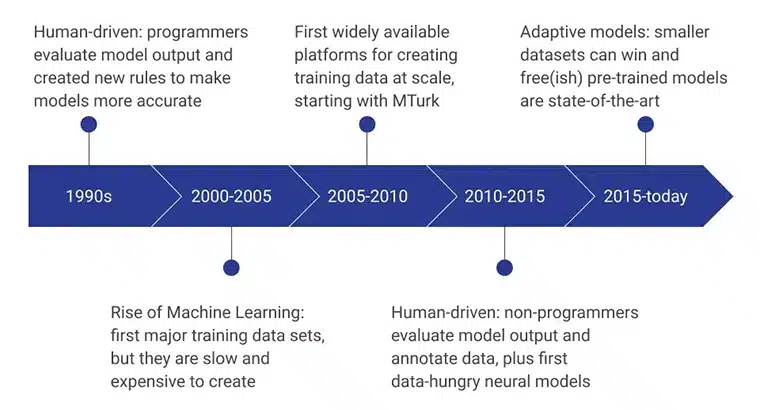
Τα αρχικά στάδια των δεδομένων εκπαίδευσης τεχνητής νοημοσύνης τροφοδοτήθηκαν από ανθρώπινους προγραμματιστές που αξιολόγησαν την έξοδο του μοντέλου επινοώντας συνεχώς νέους κανόνες που έκαναν το μοντέλο πιο αποτελεσματικό. Την περίοδο 2000 – 2005, δημιουργήθηκε το πρώτο μεγάλο σύνολο δεδομένων και ήταν μια εξαιρετικά αργή, βασισμένη στους πόρους και δαπανηρή διαδικασία. Οδήγησε στην ανάπτυξη συνόλων δεδομένων κατάρτισης σε κλίμακα και το MTurk της Amazon έπαιξε σημαντικό ρόλο στην αλλαγή της αντίληψης των ανθρώπων για τη συλλογή δεδομένων. Ταυτόχρονα, η ανθρώπινη επισήμανση και ο σχολιασμός απογειώθηκαν επίσης.
Τα επόμενα χρόνια επικεντρώθηκαν σε μη προγραμματιστές που δημιουργούν και αξιολογούν τα μοντέλα δεδομένων. Επί του παρόντος, η εστίαση είναι σε προεκπαιδευμένα μοντέλα που έχουν αναπτυχθεί χρησιμοποιώντας προηγμένες μεθόδους συλλογής δεδομένων εκπαίδευσης.
Ποσότητα σε σχέση με την ποιότητα
Κατά την αξιολόγηση της ακεραιότητας των συνόλων δεδομένων εκπαίδευσης AI παλιότερα, οι επιστήμονες δεδομένων εστίασαν σε Ποσότητα δεδομένων εκπαίδευσης AI πάνω από την ποιότητα.
Για παράδειγμα, υπήρχε μια κοινή παρανόηση ότι οι μεγάλες βάσεις δεδομένων παρέχουν ακριβή αποτελέσματα. Ο τεράστιος όγκος των δεδομένων πιστεύεται ότι είναι ένας καλός δείκτης της αξίας των δεδομένων. Η ποσότητα είναι μόνο ένας από τους κύριους παράγοντες που καθορίζουν την αξία του συνόλου δεδομένων – ο ρόλος της ποιότητας των δεδομένων αναγνωρίστηκε.
Η επίγνωση ότι την ποιότητα των δεδομένων ανάλογα με την πληρότητα των δεδομένων, αυξήθηκε η αξιοπιστία, η εγκυρότητα, η διαθεσιμότητα και η επικαιρότητα. Το πιο σημαντικό, η καταλληλότητα των δεδομένων για το έργο καθόρισε την ποιότητα των δεδομένων που συγκεντρώθηκαν.
Περιορισμοί πρώιμων συστημάτων AI λόγω ανεπαρκών δεδομένων εκπαίδευσης
Τα κακά δεδομένα εκπαίδευσης, σε συνδυασμό με την έλλειψη προηγμένων υπολογιστικών συστημάτων, ήταν ένας από τους λόγους για πολλές ανεκπλήρωτες υποσχέσεις για πρώιμα συστήματα AI.
Λόγω της έλλειψης ποιοτικών δεδομένων εκπαίδευσης, οι λύσεις ML δεν μπορούσαν να προσδιορίσουν με ακρίβεια οπτικά μοτίβα που εμποδίζουν την ανάπτυξη της νευρωνικής έρευνας. Αν και πολλοί ερευνητές εντόπισαν την υπόσχεση της αναγνώρισης της ομιλούμενης γλώσσας, η έρευνα ή η ανάπτυξη εργαλείων αναγνώρισης ομιλίας δεν μπόρεσε να πραγματοποιηθεί χάρη στην έλλειψη συνόλων δεδομένων ομιλίας. Ένα άλλο σημαντικό εμπόδιο για την ανάπτυξη εργαλείων τεχνητής νοημοσύνης προηγμένης τεχνολογίας ήταν η έλλειψη υπολογιστικών και αποθηκευτικών δυνατοτήτων των υπολογιστών.
Η στροφή στα ποιοτικά δεδομένα εκπαίδευσης
Υπήρξε μια αξιοσημείωτη αλλαγή στην επίγνωση ότι η ποιότητα του συνόλου δεδομένων έχει σημασία. Προκειμένου το σύστημα ML να μιμείται με ακρίβεια την ανθρώπινη νοημοσύνη και τις ικανότητες λήψης αποφάσεων, πρέπει να ευδοκιμεί σε δεδομένα εκπαίδευσης μεγάλου όγκου, υψηλής ποιότητας.
Σκεφτείτε τα δεδομένα ML σας ως έρευνα - τόσο μεγαλύτερο είναι δείγμα δεδομένων μέγεθος, τόσο καλύτερη είναι η πρόβλεψη. Εάν το δείγμα δεδομένων δεν περιλαμβάνει όλες τις μεταβλητές, ενδέχεται να μην αναγνωρίζει μοτίβα ή να βγάζει ανακριβή συμπεράσματα.
Οι εξελίξεις στην τεχνολογία AI και η ανάγκη για καλύτερα δεδομένα εκπαίδευσης
 Οι εξελίξεις στην τεχνολογία AI αυξάνουν την ανάγκη για ποιοτικά δεδομένα εκπαίδευσης.
Οι εξελίξεις στην τεχνολογία AI αυξάνουν την ανάγκη για ποιοτικά δεδομένα εκπαίδευσης.Η κατανόηση ότι τα καλύτερα δεδομένα εκπαίδευσης αυξάνουν την πιθανότητα αξιόπιστων μοντέλων ML οδήγησε σε καλύτερες μεθοδολογίες συλλογής δεδομένων, σχολιασμού και επισήμανσης. Η ποιότητα και η συνάφεια των δεδομένων επηρέασαν άμεσα την ποιότητα του μοντέλου AI.
 Οι εξελίξεις στην τεχνολογία AI αυξάνουν την ανάγκη για ποιοτικά δεδομένα εκπαίδευσης.
Οι εξελίξεις στην τεχνολογία AI αυξάνουν την ανάγκη για ποιοτικά δεδομένα εκπαίδευσης.Αυξημένη εστίαση στην ποιότητα και την ακρίβεια των δεδομένων
Για να αρχίσει το μοντέλο ML να παρέχει ακριβή αποτελέσματα, τροφοδοτείται από ποιοτικά σύνολα δεδομένων που περνούν από επαναληπτικά βήματα βελτίωσης δεδομένων.
Για παράδειγμα, ένας άνθρωπος μπορεί να είναι σε θέση να αναγνωρίσει μια συγκεκριμένη ράτσα σκύλου μέσα σε λίγες ημέρες μετά την εισαγωγή στη ράτσα – μέσω εικόνων, βίντεο ή αυτοπροσώπως. Οι άνθρωποι αντλούν από την εμπειρία τους και τις σχετικές πληροφορίες για να θυμούνται και να αντλούν αυτή τη γνώση όταν είναι απαραίτητο. Ωστόσο, δεν λειτουργεί τόσο εύκολα για μια Μηχανή. Το μηχάνημα πρέπει να τροφοδοτηθεί με εικόνες με σαφή σχολιασμό και ετικέτα – εκατοντάδες ή χιλιάδες – της συγκεκριμένης φυλής και άλλων φυλών για να κάνει τη σύνδεση.
Ένα μοντέλο AI προβλέπει το αποτέλεσμα συσχετίζοντας τις πληροφορίες που εκπαιδεύονται με τις πληροφορίες που παρουσιάζονται στο πραγματικό κόσμο. Ο αλγόριθμος καθίσταται άχρηστος εάν τα δεδομένα εκπαίδευσης δεν περιλαμβάνουν σχετικές πληροφορίες.
Σημασία διαφορετικών και αντιπροσωπευτικών δεδομένων εκπαίδευσης
Η αυξημένη ποικιλομορφία δεδομένων αυξάνει επίσης την ικανότητα, μειώνει την προκατάληψη και ενισχύει τη δίκαιη εκπροσώπηση όλων των σεναρίων. Εάν το μοντέλο AI εκπαιδεύεται χρησιμοποιώντας ένα ομοιογενές σύνολο δεδομένων, μπορείτε να είστε σίγουροι ότι η νέα εφαρμογή θα λειτουργεί μόνο για έναν συγκεκριμένο σκοπό και θα εξυπηρετεί έναν συγκεκριμένο πληθυσμό.Ένα σύνολο δεδομένων θα μπορούσε να είναι προκατειλημμένο προς έναν συγκεκριμένο πληθυσμό, φυλή, φύλο, επιλογές και πνευματικές απόψεις, κάτι που θα μπορούσε να οδηγήσει σε ένα ανακριβές μοντέλο.
Είναι σημαντικό να διασφαλιστεί ότι ολόκληρη η ροή της διαδικασίας συλλογής δεδομένων, συμπεριλαμβανομένης της επιλογής της ομάδας θεμάτων, της επιμέλειας, του σχολιασμού και της επισήμανσης, είναι επαρκώς διαφορετική, ισορροπημένη και αντιπροσωπευτική του πληθυσμού.
 Η αυξημένη ποικιλομορφία δεδομένων αυξάνει επίσης την ικανότητα, μειώνει την προκατάληψη και ενισχύει τη δίκαιη εκπροσώπηση όλων των σεναρίων. Εάν το μοντέλο AI εκπαιδεύεται χρησιμοποιώντας ένα ομοιογενές σύνολο δεδομένων, μπορείτε να είστε σίγουροι ότι η νέα εφαρμογή θα λειτουργεί μόνο για έναν συγκεκριμένο σκοπό και θα εξυπηρετεί έναν συγκεκριμένο πληθυσμό.
Η αυξημένη ποικιλομορφία δεδομένων αυξάνει επίσης την ικανότητα, μειώνει την προκατάληψη και ενισχύει τη δίκαιη εκπροσώπηση όλων των σεναρίων. Εάν το μοντέλο AI εκπαιδεύεται χρησιμοποιώντας ένα ομοιογενές σύνολο δεδομένων, μπορείτε να είστε σίγουροι ότι η νέα εφαρμογή θα λειτουργεί μόνο για έναν συγκεκριμένο σκοπό και θα εξυπηρετεί έναν συγκεκριμένο πληθυσμό.Το μέλλον των δεδομένων εκπαίδευσης AI
Η μελλοντική επιτυχία των μοντέλων AI εξαρτάται από την ποιότητα και την ποσότητα των δεδομένων εκπαίδευσης που χρησιμοποιούνται για την εκπαίδευση των αλγορίθμων ML. Είναι σημαντικό να αναγνωρίσουμε ότι αυτή η σχέση μεταξύ ποιότητας και ποσότητας δεδομένων είναι συγκεκριμένη για κάθε εργασία και δεν έχει σαφή απάντηση.
Τελικά, η επάρκεια ενός συνόλου δεδομένων εκπαίδευσης ορίζεται από την ικανότητά του να αποδίδει αξιόπιστα καλά για τον σκοπό που έχει κατασκευαστεί.
Πρόοδοι στις τεχνικές συλλογής δεδομένων και σχολιασμού
Δεδομένου ότι η ML είναι ευαίσθητη στα τροφοδοτούμενα δεδομένα, είναι ζωτικής σημασίας να εξορθολογιστούν οι πολιτικές συλλογής δεδομένων και σχολιασμού. Σφάλματα στη συλλογή δεδομένων, την επιμέλεια, την εσφαλμένη παρουσίαση, τις ελλιπείς μετρήσεις, το ανακριβές περιεχόμενο, την επικάλυψη δεδομένων και τις εσφαλμένες μετρήσεις συμβάλλουν στην ανεπαρκή ποιότητα των δεδομένων.
Η αυτοματοποιημένη συλλογή δεδομένων μέσω της εξόρυξης δεδομένων, της απόξεσης ιστού και της εξαγωγής δεδομένων ανοίγει το δρόμο για ταχύτερη παραγωγή δεδομένων. Επιπλέον, τα προσυσκευασμένα σύνολα δεδομένων λειτουργούν ως τεχνική συλλογής δεδομένων γρήγορης επιδιόρθωσης.
Το crowdsourcing είναι μια άλλη πρωτοποριακή μέθοδος συλλογής δεδομένων. Αν και η ακρίβεια των δεδομένων δεν μπορεί να επιβεβαιωθεί, είναι ένα εξαιρετικό εργαλείο για τη συλλογή δημόσιας εικόνας. Τέλος, εξειδικευμένο συλλογή δεδομένων Οι ειδικοί παρέχουν επίσης δεδομένα που προέρχονται για συγκεκριμένους σκοπούς.
Αυξημένη έμφαση σε ηθικά ζητήματα στα δεδομένα εκπαίδευσης
Με τις ραγδαίες εξελίξεις στην τεχνητή νοημοσύνη, έχουν εμφανιστεί αρκετά ηθικά ζητήματα, ειδικά στη συλλογή δεδομένων εκπαίδευσης. Ορισμένα ηθικά ζητήματα στη συλλογή δεδομένων εκπαίδευσης περιλαμβάνουν τη συγκατάθεση μετά από ενημέρωση, τη διαφάνεια, την προκατάληψη και το απόρρητο των δεδομένων.Δεδομένου ότι τα δεδομένα περιλαμβάνουν πλέον τα πάντα, από εικόνες προσώπου, δακτυλικά αποτυπώματα, ηχογραφήσεις φωνής και άλλα κρίσιμα βιομετρικά δεδομένα, καθίσταται εξαιρετικά σημαντικό να διασφαλιστεί η τήρηση νομικών και ηθικών πρακτικών για την αποφυγή δαπανηρών αγωγών και βλάβης της φήμης.
Η δυνατότητα για ακόμη καλύτερης ποιότητας και ποικίλα δεδομένα προπόνησης στο μέλλον
Υπάρχει μια τεράστια δυνατότητα για υψηλής ποιότητας και ποικίλα δεδομένα εκπαίδευσης στο μέλλον. Χάρη στην επίγνωση της ποιότητας των δεδομένων και στη διαθεσιμότητα των παρόχων δεδομένων που ανταποκρίνονται στις απαιτήσεις ποιότητας των λύσεων τεχνητής νοημοσύνης.
Οι σημερινοί πάροχοι δεδομένων είναι έμπειροι στη χρήση πρωτοποριακών τεχνολογιών για την ηθική και νομική προμήθεια τεράστιων ποσοτήτων διαφορετικών συνόλων δεδομένων. Έχουν επίσης εσωτερικές ομάδες για να επισημαίνουν, να σχολιάζουν και να παρουσιάζουν τα δεδομένα προσαρμοσμένα για διαφορετικά έργα ML.
 Με τις ραγδαίες εξελίξεις στην τεχνητή νοημοσύνη, έχουν εμφανιστεί αρκετά ηθικά ζητήματα, ειδικά στη συλλογή δεδομένων εκπαίδευσης. Ορισμένα ηθικά ζητήματα στη συλλογή δεδομένων εκπαίδευσης περιλαμβάνουν τη συγκατάθεση μετά από ενημέρωση, τη διαφάνεια, την προκατάληψη και το απόρρητο των δεδομένων.
Με τις ραγδαίες εξελίξεις στην τεχνητή νοημοσύνη, έχουν εμφανιστεί αρκετά ηθικά ζητήματα, ειδικά στη συλλογή δεδομένων εκπαίδευσης. Ορισμένα ηθικά ζητήματα στη συλλογή δεδομένων εκπαίδευσης περιλαμβάνουν τη συγκατάθεση μετά από ενημέρωση, τη διαφάνεια, την προκατάληψη και το απόρρητο των δεδομένων.Συμπέρασμα
Είναι σημαντικό να συνεργάζεστε με αξιόπιστους προμηθευτές με πλήρη κατανόηση των δεδομένων και της ποιότητας ανάπτυξη μοντέλων τεχνητής νοημοσύνης υψηλής τεχνολογίας. Η Shaip είναι η κορυφαία εταιρεία σχολιασμού που είναι ικανή να παρέχει προσαρμοσμένες λύσεις δεδομένων που ανταποκρίνονται στις ανάγκες και τους στόχους του έργου AI σας. Συνεργαστείτε μαζί μας και εξερευνήστε τις ικανότητες, τη δέσμευση και τη συνεργασία που φέρνουμε στο τραπέζι.


